Conversational AI tools for Marketing Mix Modeling (MMM) and incrementality testing are a new product category that lets marketing teams measure and optimize media spend through natural language, without needing a data analyst to interpret every report. This article evaluates five vendors providing a tool for this category: Sellforte, Lifesight, Triple Whale, Fospha, and Mutinex, across 48 criteria derived from 1,660 real marketer prompts and 700+ customer discussions.
Disclaimer: This evaluation was designed and published by Sellforte, one of the vendors evaluated. All scores were assigned by Claude and ChatGPT based on publicly available information as of June 2026. A score of 0 means no public evidence was found, not that the capability does not exist. Vendors may submit documentation for re-evaluation at research@sellforte.com. Buyers should independently verify capabilities before purchasing decisions.
Summary: Best Conversational AI tools for Marketing Mix Modeling (MMM) and Incrementality Testing in 2026
We asked Claude and ChatGPT to evaluate 5 vendors providing conversational AI tools for Marketing Mix Modeling (MMM) and Incrementality testing, based on 48 criteria in 9 categories that were derived from more than 1,660 real AI prompts and 700 discussions with marketers and marketing analytics professionals. Evaluated tools include Sellforte, Lifesight, Triple Whale, Fospha and Mutinex. Here is how the they compare:
| Sellforte | Lifesight | Triple Whale | Fospha | Mutinex | Max | |
|---|---|---|---|---|---|---|
| 1. Marketing Data Reporting via conversational AI | 4.0 | 4.0 | 3.6 | 2.1 | 4.0 | 4 |
| 2. Historical Performance Insights & Causal Explanation via conversational AI | 4.6 | 4.4 | 4.3 | 3.4 | 4.4 | 5 |
| 3. Channel-Level Optimization with conversational AI | 4.4 | 4.6 | 3.0 | 2.5 | 4.5 | 5 |
| 4. Campaign & Ad Set-Level Optimization for digital channels with conversational AI | 4.4 | 2.4 | 2.8 | 2.5 | 1.0 | 6 |
| 5. Incrementality Testing with conversational AI | 4.3 | 2.5 | 2.9 | 0.5 | 0.1 | 5 |
| 6. Agentic Execution & Autonomy | 2.1 | 2.8 | 3.9 | 1.6 | 0.1 | 4 |
| 7. AI's UX & Conversational Interface | 3.5 | 4.5 | 6.5 | 6.5 | 4.0 | 8 |
| 8. Analytical Backbone of the Conversational AI | 3.5 | 3.0 | 3.0 | 2.8 | 2.3 | 4 |
| 9. Enterprise-Grade Platform | 5.5 | 5.0 | 2.8 | 3.3 | 4.0 | 7 |
| Total score out of 48 | 36.3 | 33.1 | 32.6 | 25.1 | 24.4 | 48 |
Note: This comparison was designed and published by Sellforte, one of the vendors evaluated. The scoring was conducted with Claude and ChatGPT. Score of 0 means the LLMs could not verify a capability from public sources.
Sellforte ranked highest in the comparison scoring 36.3 out of 48, followed by Lifesight (33.1 out of 48), Triple Whale (32.6 out of 48), Fospha (25.1 out of 48), and Mutinex (24.4 out of 48).
Sellforte is best for marketing teams looking for an enterprise-grade conversational AI tool that supports channel- and campaign-level media spend optimization grounded in strong analytical backbone covering MMM, incrementality testing and incrementality-corrected attribution. Sellforte is particularly strong in Retail and Ecommerce.
Lifesight is best for ecommerce and consumer brand marketers requiring a conversational AI for media spend optimization based on Lifesight's analytics, but for whom full incrementality test coverage is not a priority.
Triple Whale is best for small and mid-sized ecommerce businesses requiring a strong conversational AI tool, but for whom incrementality-based optimization at the campaign & ad set level with enterprise-grade MMM is not a priority.
Fospha is best for small ecommerce businesses requiring conversational AI for historical performance reporting based on Fospha measurement, but for whom future-looking optimization and enterprise-grade measurement platform covering also causal experimentation is not a priority.
Mutinex is best for large enterprises who require a conversational AI tool for optimizing media spend across channels. Mutinex is particularly strong in the CPG / FMCG segment.
Introduction and Table of Contents
Conversational AI tools for Marketing Mix Modeling (MMM) and Incrementality Testing are a new, rapidly developing product category. We are excited to publish one of the first in-depth tool evaluation research article on the topic.
While platform and tool reviews are typically high-level tool listings with limited remarks of each tool, our goal with this article was far more ambitious: we wanted to create an evidence-based and verifiable comparison of conversational AI tools for MMM and Incrementality Testing, grounded in research on real usage patterns and requirements that modern marketers and marketing analytics teams have in 2026. We also wanted to make the evaluation re-producible by anyone, please see instructions later in the article.
Here's what we're covering in this article:
- Quick Summary: Best Conversational AI tools for MMM and Incrementality Testing in 2026
- What are AI tools for MMM and Incrementality Testing?
- Research Methodology: Evaluation Criteria
- Research Methodology: Evaluation and Scoring
- In-depth Comparison of AI tools for MMM and Incrementality Testing
- Frequently Asked Questions
- Change log
- Evaluation Dates by Vendor and LLM
- Limitations & Disclosures
- Further Reading
What are Conversational AI tools for MMM and Incrementality Testing?
Conversational AI tools for MMM and Incrementality Testing help marketers measure media performance, optimize marketing spend allocation and execute optimization actions through a conversational, natural language AI interface.
Unlike traditional dashboards, which require users to navigate filters and find the right charts, AI tools for MMM and Incrementality Testing let marketers interact with their measurement stack the way they would with a senior analyst: "Why did revenue drop last week?", "What's the incremental ROAS of Meta vs. TikTok?", "What happens if I cut re-allocate 20% from retargeting to prospecting?".
Unlike generic LLM tools (ChatGPT, Claude, Gemini), AI tools for MMM and Incrementality Testing are purpose-built for marketing, grounded on advertiser's actual data and real incrementality-based measurement models.
To illustrate a conversational AI tool for MMM and Incrementality Testing, below is a screenshot from Sellforte:
Categories of conversational AI tools for MMM and Incrementality Testing: What types of tools exist?
There's three categories of conversational AI tools for MMM and Incrementality Testing, from basic to advanced
1. Conversational AI tools for Marketing Data Reporting provide marketers fast access to raw data from advertising platforms, ecommerce platforms or analytics tools. The tools in this category are not connected to an MMM or incrementality testing. These types of tools are commonly found from for example from data connector companies. Since they lack the analytical backbone for measuring the true incremental impact of advertising, their relevance for optimizing media spend allocation is limited.
2. Conversational AI tools for channel-level optimization help marketers optimize channel-level media spend allocation. Marketers can ask questions, such as "What's an optimal budget allocation for the next quarter?". These types of tools are commonly found from traditional Marketing Mix Modeling companies, who have started building AI on top of their MMM. While highly useful for channel-level spend optimization, these tools have a limitation: they are not able to offer insights on the campaign & ad set level where the practical execution of media spend optimization happens. These means that they are also not able to offer autonomous agents for executing media spend optimization actions.
3. Agentic MMM and Incrementality testing tools for Campaign & Ad set level Execution help marketers measure marketing ROI, optimize marketing spend allocation, and execute bidding changes on advertising platforms. This is technologically the most advanced AI tool category. These tools operate on the campaign & ad set level, enabling marketers execute bidding changes on ad platforms. These platforms provide AI Agents for autonomous media spend optimization, based on true incrementality. Agentic MMM tools are part of this category.
How do Conversational AI tools for MMM and Incrementality Testing work?
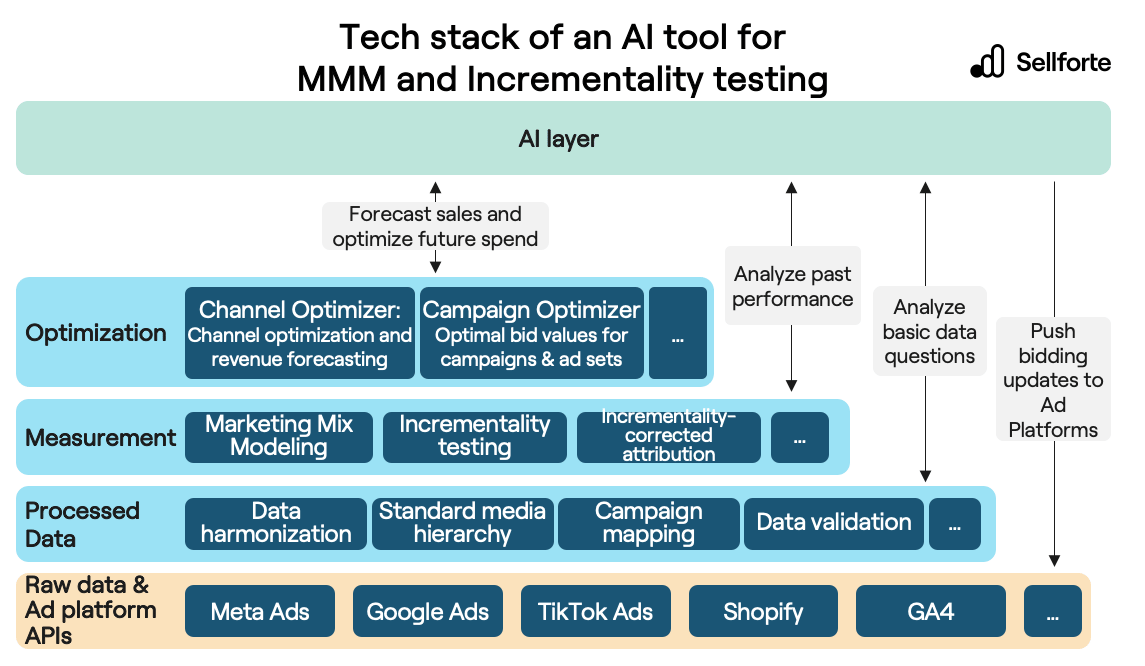
Conversational AI tools for MMM and Incrementality Testing are an additional layer in an existing MMM and Incrementality Testing technology stack, leveraging all the other layers in the technology stack to answer marketer's questions.
Here's a few examples:
- For basic data questions ("What was the spend on Google Performance Max last month?"), the AI connects with the Processed Data layer
- For questions on past performance ("What was the ROI for Google Performance Max last month?"), the AI connect with the data science layer, which has MMM's historical performance results
- For spend optimization questions ("What's the optimal spend allocation across channels for the next month?") , the AI connects with dynamic tools in the Optimization tools -layer
The tech stack of a conversational AI tool for MMM and Incrementality Testing is illustrated in the image below, using Sellforte as an example:
Research Methodology: Evaluation Criteria
Each Conversational AI tool for MMM and Incrementality Testing in this article is evaluated against criteria that we formed through extensive primary research based on three lenses. These criteria were developed and this evaluation was authored by Sellforte, one of the platforms included in the comparison.
1. Actual AI tool usage today based on real prompts. We first investigated how marketers are actually using AI tools for MMM and Incrementality Testing today. We collected 1,660 prompts recently made in Sellforte's conversational AI tool, Sellforte AI, by marketers and marketing analytics professionals, and categorized them based on the topic and specific use-case. We included all prompts, independent of whether Sellforte AI was capable of answering marketers.
2. Communicated expectations towards conversational AI tools. We investigated the expectations that marketers and marketing analytics teams have for AI tools for MMM and Incrementality Testing. We analyzed AI-related comments and statements in more than 700 discussions with Sellforte customers and prospects, including marketers, marketing analytics leads, and data scientists working in advertising-heavy industries such as retail, ecommerce, DTC, travel & hospitality, and restaurants. We also reviewed AI requirements in recent MMM and Incrementality Testing RFP documentations.
3. Existing capabilities in Conversational AI tools for MMM and Incrementality Testing in the market. We reviewed 78 vendors operating in the marketing measurement space. We evaluated whether the vendors had an AI offering, and if so, we synthesized the capabilities that they communicate on the website, technical documentation or demos.
The result: 48 evaluation criteria across 9 categories.
Evaluation criteria for Conversational AI tools for MMM and Incrementality Testing
This table summarizes our evaluation criteria for AI tools for MMM and Incrementality Testing:
| ID | Category | Criterion | What it means |
|---|---|---|---|
| 1. Marketing data reporting via conversational AI | |||
| 1.1 | Marketing data reporting via conversational AI | AI reports sales progress for online sales | AI can report and summarize online sales development. |
| 1.2 | Marketing data reporting via conversational AI | AI reports sales progress for offline store sales | AI can report and summarize sales development in offline store sales. |
| 1.3 | Marketing data reporting via conversational AI | AI reports digital media data (spend, impressions, clicks) | AI reports digital media data across Meta, Google, TikTok, and other major paid platforms. |
| 1.4 | Marketing data reporting via conversational AI | AI reports offline media data | AI reports data for offline media, such as TV. |
| 2. Historical performance insights & causal explanation via conversational AI | |||
| 2.1 | Historical performance insights & causal explanation via conversational AI | AI measures incremental ROAS and incremental revenue for each digital channel | AI reports true incremental impact, not just last-click or platform-reported ROAS, for each digital channel. |
| 2.2 | Historical performance insights & causal explanation via conversational AI | AI measures incremental ROAS and incremental revenue for each offline channel | AI reports incremental ROAS and revenue for offline channels such as TV, OOH, and radio. |
| 2.3 | Historical performance insights & causal explanation via conversational AI | AI reports promotion-driven revenue, in addition to media-driven | AI surfaces how promotions and pricing changes contributed to sales, not just paid media. |
| 2.4 | Historical performance insights & causal explanation via conversational AI | AI-reported incremental ROAS is updated daily | The AI provides daily measurement of incremental ROAS based on MMM, not just weekly, monthly, or quarterly model refreshes. |
| 2.5 | Historical performance insights & causal explanation via conversational AI | AI explains why performance has changed | AI ties sales changes to specific drivers: promotions, seasonality, weather, media saturation, and more. |
| 3. Channel-level optimization with conversational AI | |||
| 3.1 | Channel-level optimization with conversational AI | AI recommends optimal budget allocation by channel | AI recommends optimal budget allocation across channels (Meta, Google, TikTok, etc.). |
| 3.2 | Channel-level optimization with conversational AI | AI forecasts total revenue based on optimal budget allocation | AI forecasts expected total revenue under the recommended allocation. |
| 3.3 | Channel-level optimization with conversational AI | AI provides miROAS and response curves for each channel | AI provides Marginal Incremental ROAS (miROAS) and saturation / response curves per channel. |
| 3.4 | Channel-level optimization with conversational AI | AI supports basic custom scenario planning (e.g., "what if I cut Meta by 20%?") | Users can simulate custom what-if scenarios in natural language and see forecasted revenue outcomes. |
| 3.5 | Channel-level optimization with conversational AI | AI supports advanced scenario planning in natural language (constraints, multi-dimensional optimization…) | Users can ask complex scenario questions including constraints, multi-dimensional optimization, and marginal budget recommendations ("where should my next €500K go?"). |
| 4. Campaign & ad set-level optimization for Digital Channels with conversational AI | |||
| 4.1 | Campaign & ad set-level optimization for Digital Channels with conversational AI | AI provides incremental ROAS of each campaign & ad set | AI reports incremental revenue and ROAS at the individual campaign and ad set level, not just at the channel level. |
| 4.2 | Campaign & ad set-level optimization for Digital Channels with conversational AI | AI provides comparison of incremental ROAS to last-click and ad platform attribution ROAS | AI shows the delta between what the ad platform claims and what the model estimates is actually incremental, by campaign and ad set. |
| 4.3 | Campaign & ad set-level optimization for Digital Channels with conversational AI | AI provides miROAS for each campaign & ad set | AI provides Marginal Incremental ROAS at the campaign and ad set level to inform bidding decisions. |
| 4.4 | Campaign & ad set-level optimization for Digital Channels with conversational AI | AI recommends optimal spend for each campaign & ad set | AI recommends optimal spend/budget for each campaign and ad set. |
| 4.5 | Campaign & ad set-level optimization for Digital Channels with conversational AI | AI recommends optimal bid value for each campaign & ad set | AI recommends specific bid values (e.g., Target ROAS) per campaign and ad set for execution on ad platforms. |
| 4.6 | Campaign & ad set-level optimization for Digital Channels with conversational AI | AI provides pre/post analysis for each bidding change | After a bidding or budget change is applied, the AI measures the actual impact and provides a pre/post comparison at the campaign & ad set level. |
| 5. Incrementality testing with conversational AI | |||
| 5.1 | Incrementality testing with conversational AI | AI can summarize results for Geo Tests | AI generates detailed reports for geo incrementality tests, including iROAS and confidence intervals. |
| 5.2 | Incrementality testing with conversational AI | AI can summarize results for Own Media A/B tests (e.g. leaflet tests) | AI generates detailed reports for A/B tests for own media, such as leaflet tests. |
| 5.3 | Incrementality testing with conversational AI | The platform ingests Meta Conversion Lift tests, and the AI can summarize their findings | The platform ingests Meta Conversion Lift tests, and the AI can generate detailed reports based on the test. |
| 5.4 | Incrementality testing with conversational AI | AI provides incrementality testing recommendations | AI recommends what to prioritize for incrementality testing next (e.g. geo testing, A/B testing, or conversion lift testing). |
| 5.5 | Incrementality testing with conversational AI | AI provides incrementality test design recommendations | AI recommends incrementality test designs, including control group selection, test duration, and statistical power requirements. |
| 6. Agentic execution & autonomy | |||
| 6.1 | Agentic execution & autonomy | AI can push daily spend/budget changes to Meta, Google, TikTok APIs | The AI can execute daily spend/budget changes directly on major ad platforms via API. |
| 6.2 | Agentic execution & autonomy | AI can push bidding changes (e.g., Target ROAS) to Meta, Google, TikTok APIs | The AI can execute bidding parameter changes (e.g. Target ROAS) directly on major ad platforms via API. |
| 6.3 | Agentic execution & autonomy | AI's level of autonomy for execution can be configured | The platform supports a configurable spectrum: insight-only → recommendation-only → human-approved execution → fully autonomous execution. Users choose per use case. |
| 6.4 | Agentic execution & autonomy | Proactive insights & alerts via AI | AI surfaces anomalies, narratives, and scheduled reports proactively via Slack or email, without the user having to ask. |
| 7. AI's UX & conversational interface | |||
| 7.1 | UX & conversational interface | Includes tables and charts inline in AI responses | AI inlines data visualizations directly inside chat responses, not just text. |
| 7.2 | UX & conversational interface | AI has conversation history & multi-turn context retention | Follow-up questions retain prior context: dimensions, filters, time windows, and named entities. "What about for the next 8 weeks?" knows what "next" refers to. |
| 7.3 | UX & conversational interface | Allows convenient export of AI outputs (e.g., PDF, Slides, CSV) | AI outputs can be exported to PDF, Slides, or CSV for sharing outside the platform. |
| 7.4 | UX & conversational interface | AI grounds answers in data, providing links from outputs to deep-dive dashboards | AI outputs link out to deep-dive dashboards or detail views for further investigation, connecting the chat to the underlying data. |
| 7.5 | UX & conversational interface | AI operates in embedded and multi-window mode (chat + dashboard side-by-side) | The AI chat can be shown side-by-side with a dashboard, allowing users to submit prompts about what they are viewing. |
| 7.6 | UX & conversational interface | AI shows its reasoning steps and logic while answering | The AI surfaces its reasoning steps, the data sources it pulled from, and the assumptions behind each answer as the answer is being constructed. |
| 7.7 | UX & conversational interface | AI handles non-English questions in production | AI responds accurately in the user's language for at least 5 major languages, maintaining domain accuracy, not just translating. |
| 7.8 | UX & conversational interface | AI can be accessed via MCP server / external LLM | The tool exposes data via MCP server or equivalent, allowing external LLMs (Claude, ChatGPT, Cursor) to query it directly. |
| 8. Analytical backbone of the Conversational AI | |||
| 8.1 | Analytical backbone of the Conversational AI | AI provides deterministic, model-backed answers with Bayesian MMM as backbone | The AI's recommendations are grounded in a Bayesian Marketing Mix Model, not last-click attribution or descriptive analytics. |
| 8.2 | Analytical backbone of the Conversational AI | Bayesian MMM used by the AI is calibrated with incrementality tests | The MMM is calibrated against real incrementality test results, with priors and posteriors informed by causal experiments. |
| 8.3 | Analytical backbone of the Conversational AI | AI reports model validation and other modelling KPIs | The tool reports model validation metrics (R², MAPE, posterior predictive checks, holdout performance) so users can assess model quality. |
| 8.4 | Analytical backbone of the Conversational AI | Model calibration & configuration settings (e.g., priors) are auditable and editable in a self-serve UI | Customers can inspect and configure model priors and other key parameters in a self-serve UI, not just accept the model as a black box. |
| 9. Enterprise-grade platform | |||
| 9.1 | Enterprise-grade platform | At least 10 public reference customers from $1B+ revenue brands | Proven track record with large, sophisticated advertisers, not just mid-market or DTC brands. |
| 9.2 | Enterprise-grade platform | SOC 2, ISO 27001, or audited IT security by a third-party cyber security auditor | Independently verified security posture, a baseline requirement for enterprise IT procurement. |
| 9.3 | Enterprise-grade platform | Data residency: geography option between US and EU | Customers can choose where their data is stored, critical for GDPR compliance in Europe. |
| 9.4 | Enterprise-grade platform | Multi-cloud: option between AWS, GCP, and Azure | Deployment flexibility to match the customer's existing cloud infrastructure. |
| 9.5 | Enterprise-grade platform | Supports single sign-on (SSO) for enterprises | Enterprise authentication via SSO, required by most large-company IT policies. |
| 9.6 | Enterprise-grade platform | Customer data is not shared to a third-party LLM (LLM is deployed in a customer-specific cloud container) | AI inference runs within isolated cloud infrastructure; customer data does not egress to third-party LLM APIs such as OpenAI. |
| 9.7 | Enterprise-grade platform | Hands-on demo or trial of the AI is available without sales-call gating | A real, clickable demo of the AI is publicly accessible without requiring a sales call, a signal of product confidence and evaluation friendliness. |
Let's next cover briefly what each of these categories mean and why they matter.
Category 1. Marketing data reporting via conversational AI
This category measures AI tools' capabilities to provide basic marketing data reporting.
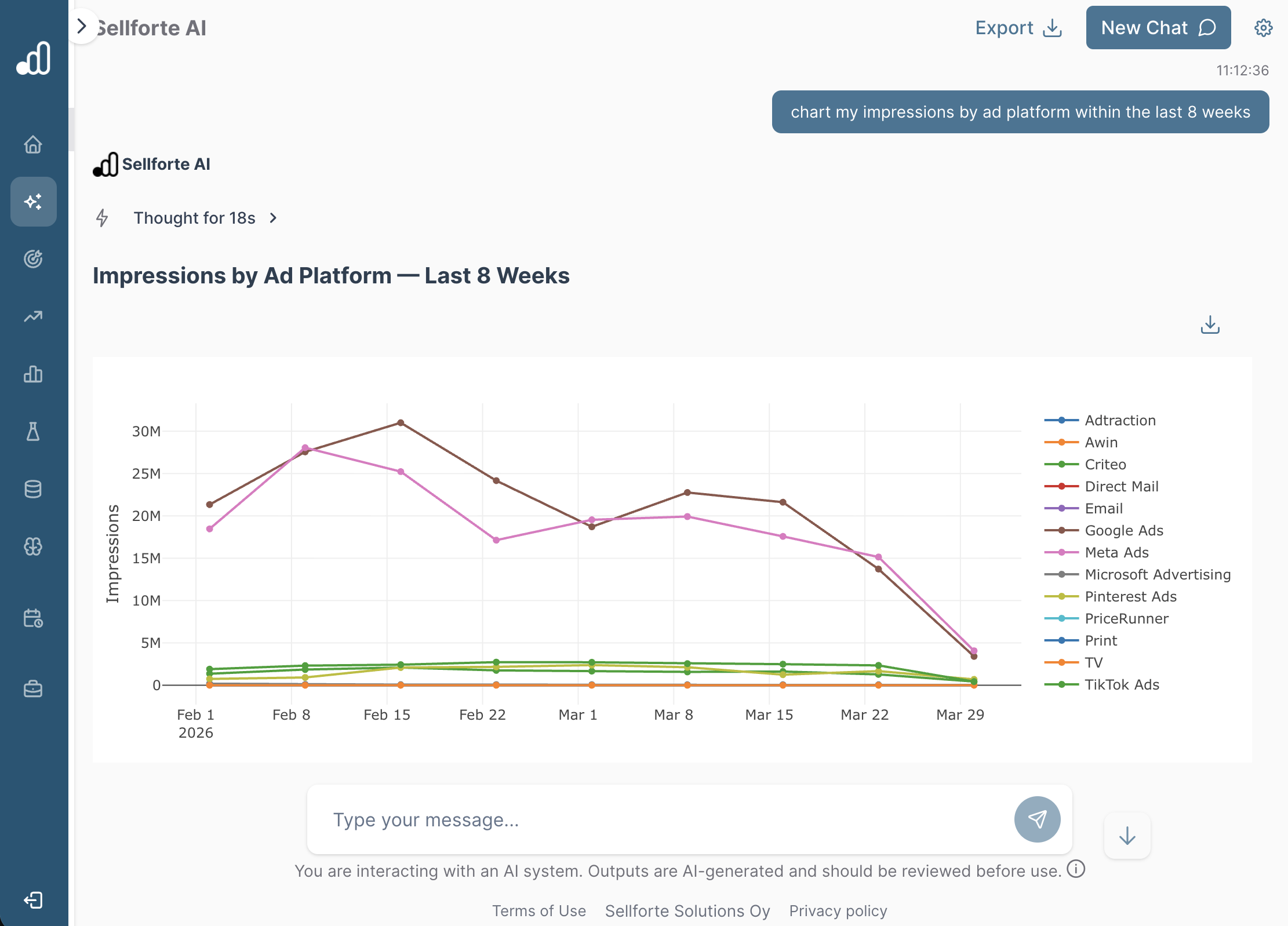
Summarizing historical data is the foundation for any marketing measurement AI tool for MMM and Incrementality Testing. At the simplest level, this means surfacing raw data from ad platforms and ecommerce platforms, such as clicks, impressions, conversions, and ecommerce sales. Enterprise-grade platforms also cover offline store sales and offline media, which might require a data warehouse connection in the backend.
To illustrate marketing data reporting in action, below is a chart from Sellforte showing how impressions have developed across ad platforms for the last 8 weeks.
Category 2. Historical performance insights & causal explanation via conversational AI
This category measures AI tools' capabilities to provide historical performance insights grounded in true incremental sales impact of media, and ability to explain the causal drivers for performance changes.
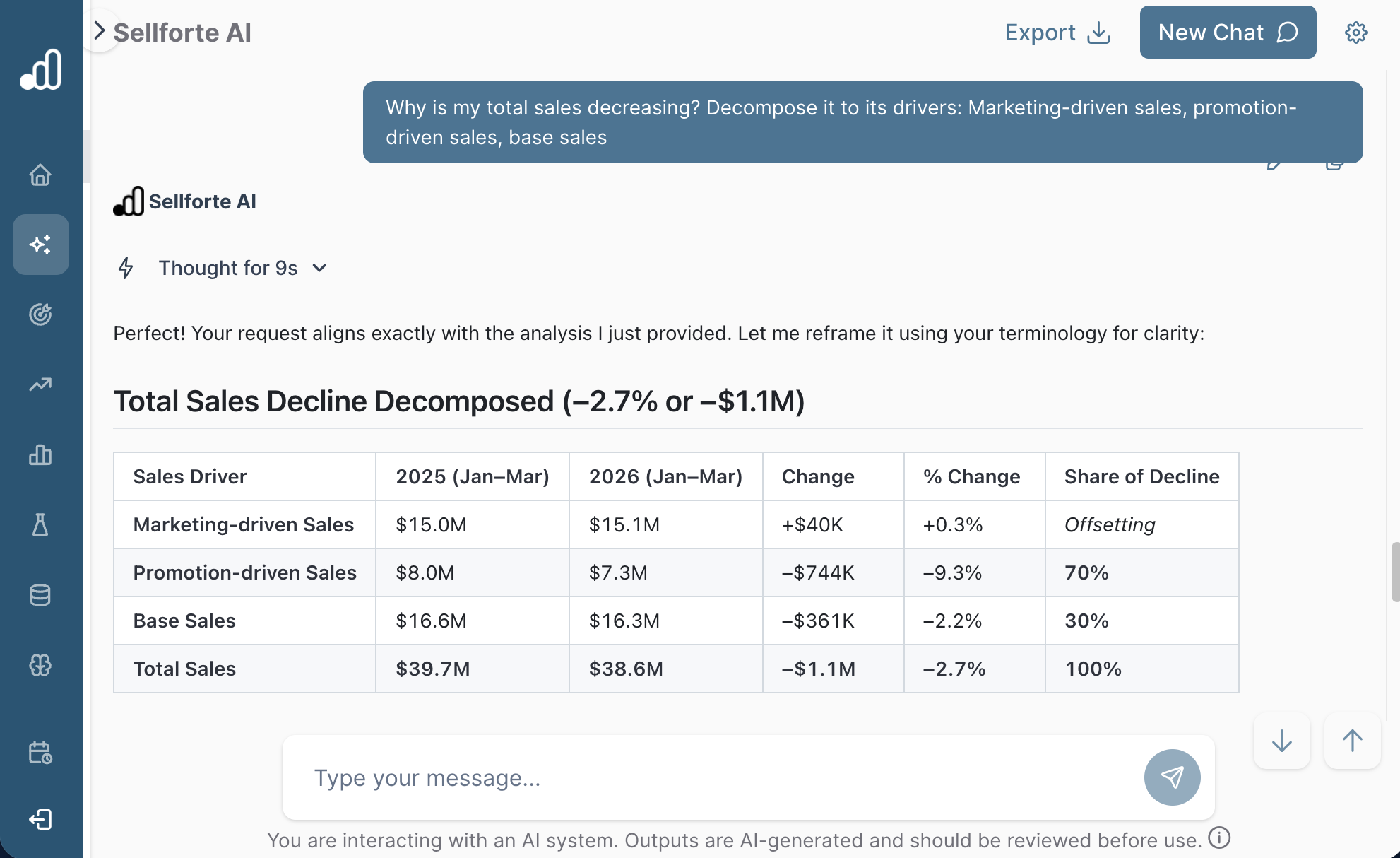
While some AI tools for MMM and Incrementality Testing are satisfied reporting ROAS from last-click or ad platform attribution, modern AI tools are measuring the true incremental ROAS of each channel and campaign. Most advanced marketing AI tools can also explain the causal drivers behind historical KPI changes, such as changes in base sales, promotion-driven sales, seasonality, or weather.
To illustrate causal explanation in action, below is a screenshot from Sellforte decomposing year-over-year sales decline into its drivers.
Category 3. Channel-level optimization with conversational AI
This category measures AI tools' capabilities to help marketers optimize media spend allocation across channels. While the two previous categories covered reporting, telling you what happened, we now move to optimization, which tells you what to do next. This is where an AI tool starts becoming truly valuable for marketing teams.
Modern AI tools for MMM and Incrementality Testing can recommend spend reallocation across channels and forecast the revenue impact of recommendations. They can answer "what if I cut Meta by 20% and shift it to YouTube?" in seconds rather than weeks. To do this credibly, the AI needs access to an optimization tool that leverages Marginal Incremental ROAS (miROAS) and Advertising Response Curves for each channel, and can project total revenue under different allocation scenarios.
The most sophisticated AI tools for MMM and Incrementality Testing go further: handling natural-language constraints, multi-dimensional optimization across channel and geography, and marginal recommendations for "if I got an extra €500K, where should it go?"
To illustrate channel-level optimization in action, below is a screenshot from Sellforte recommending optimal spend by channel for the next 3 months.
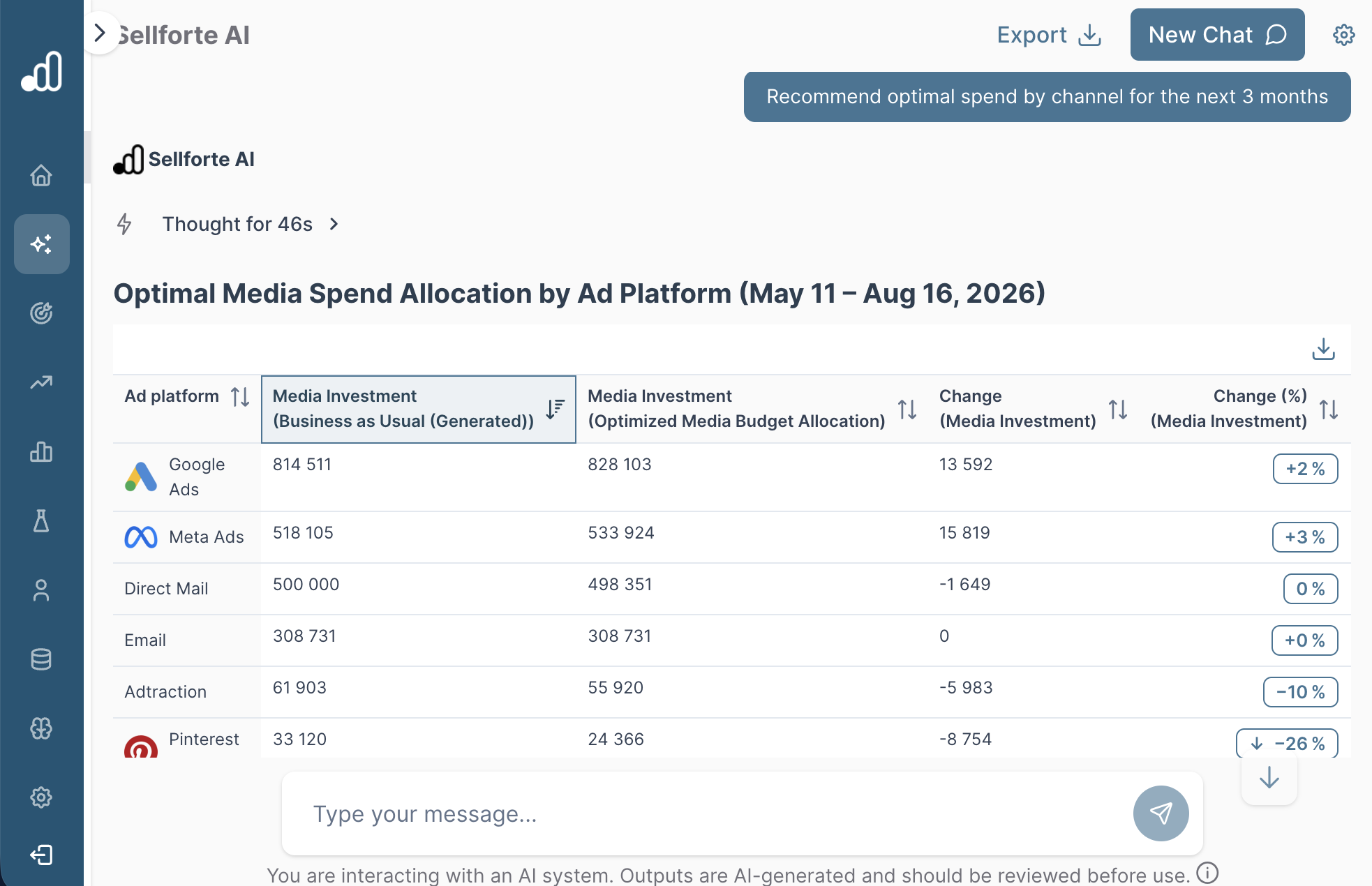
Category 4. Campaign & Ad set -level optimization for Digital Channels with conversational AI
This category measures AI tools' capabilities to support spend optimization on tactical level: optimizing spend across campaigns and ad sets within digital channels.
Campaign and ad set level is the most important granularity of optimization, because that's where budget execution practically happens. A budget shift from Meta to TikTok at the channel level is meaningless until it's executed as specific budget and bid changes across dozens or hundreds of individual campaigns and ad sets.
Most AI tools for MMM and Incrementality Testing that handle channel-level optimization don't follow through to the campaign layer. The technical bar is higher here, as this level of optimization requires reliable reliable estimation of campaign and ad set level miROAS.
To illustrate campaign and ad set level optimization in action, below is a screenshot from Sellforte recommending Target ROAS bidding changes for specific Google Ads campaigns
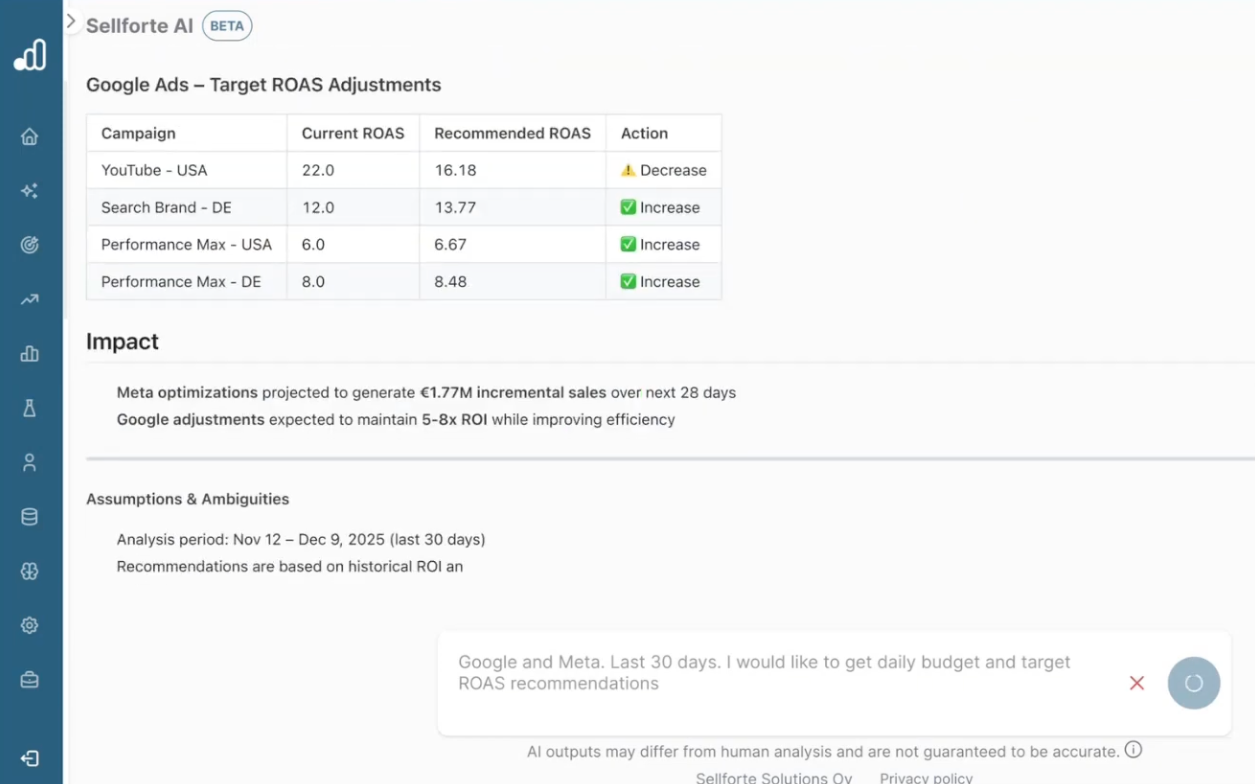
Category 5. Incrementality testing with conversational AI
This category measures AI tools' capabilities to analyze and plan incrementality tests.
Incrementality testing is used in modern measurement to calibrate Marketing Mix Models, as they can provide ground truth for a channel's incremental ROAS at a specific point in time and at a specific spend level. Advanced AI tools for MMM and Incrementality Testing have access to an incrementality test library that contain all incrementality tests done by a company, across geo tests, own media A/B tests and conversion lift tests. They can summarize the main insights from tests, including iROAS and confidence intervals. The most advanced tools also help recommending channels to tests, as well as give guidance for test design.
To illustrate how modern AI tools for MMM and Incrementality Testing can integrate with incrementality tests, below is a screenshot from Sellforte embedding AI into an incrementality testing dashboard providing a summary of how to interpret a test.
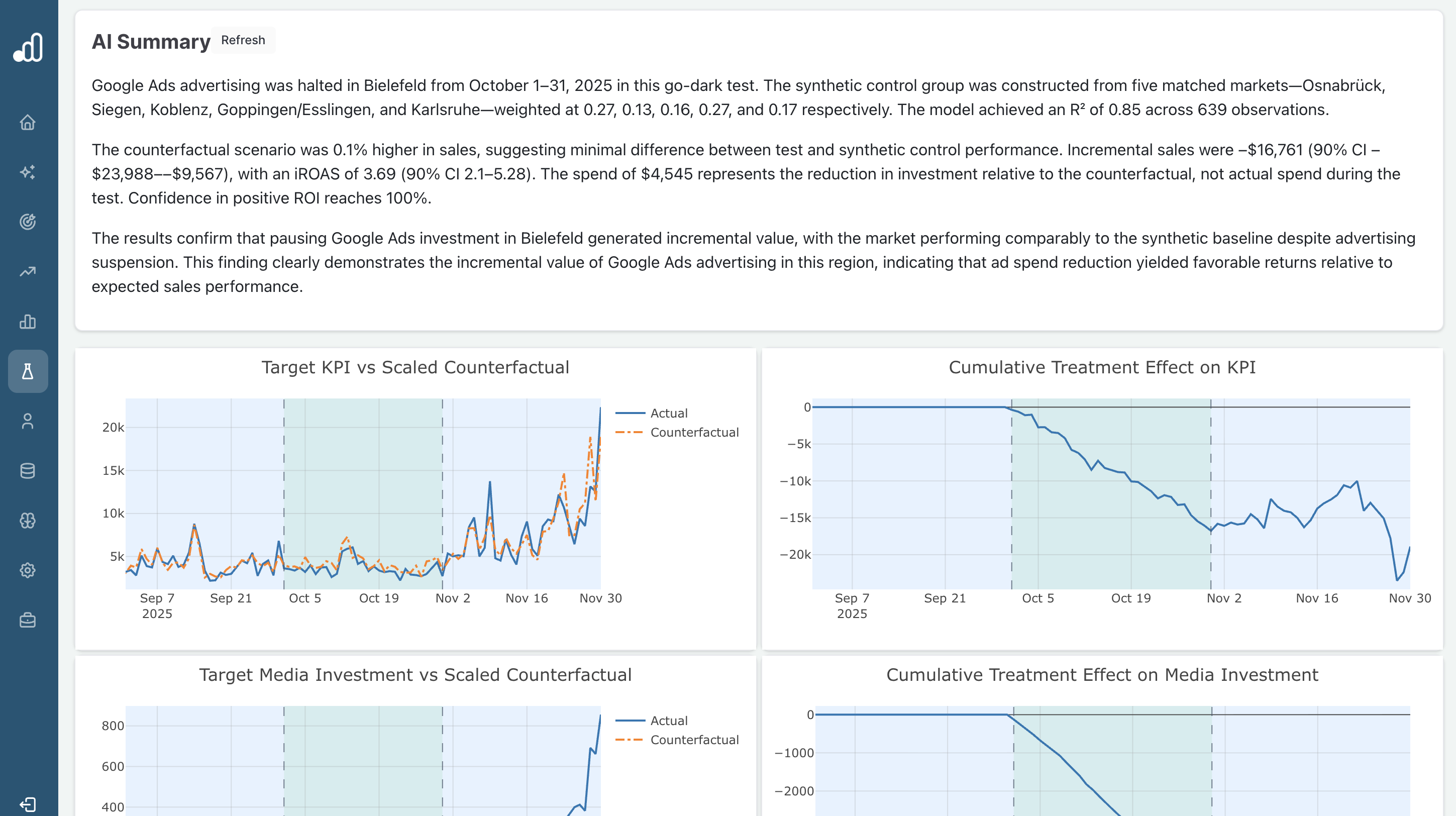
Category 6. Agentic Execution & Autonomy
This category measures AI tools' capabilities for agentic execution.
The next generation of AI tools for MMM and Incrementality Testing have agents that take action by adjusting bidding parameters directly in ad platforms. This is a fundamentally different product category, and it requires different design choices: clear autonomy boundaries, approval workflows for high-impact actions, audit logs, and rollback capabilities.
To illustrate how modern AI tools for MMM and Incrementality Testing can adjust bidding parameters, below is a screenshot from Sellforte's approval flow for adjusting Target ROAS for a Google Ads campaign.
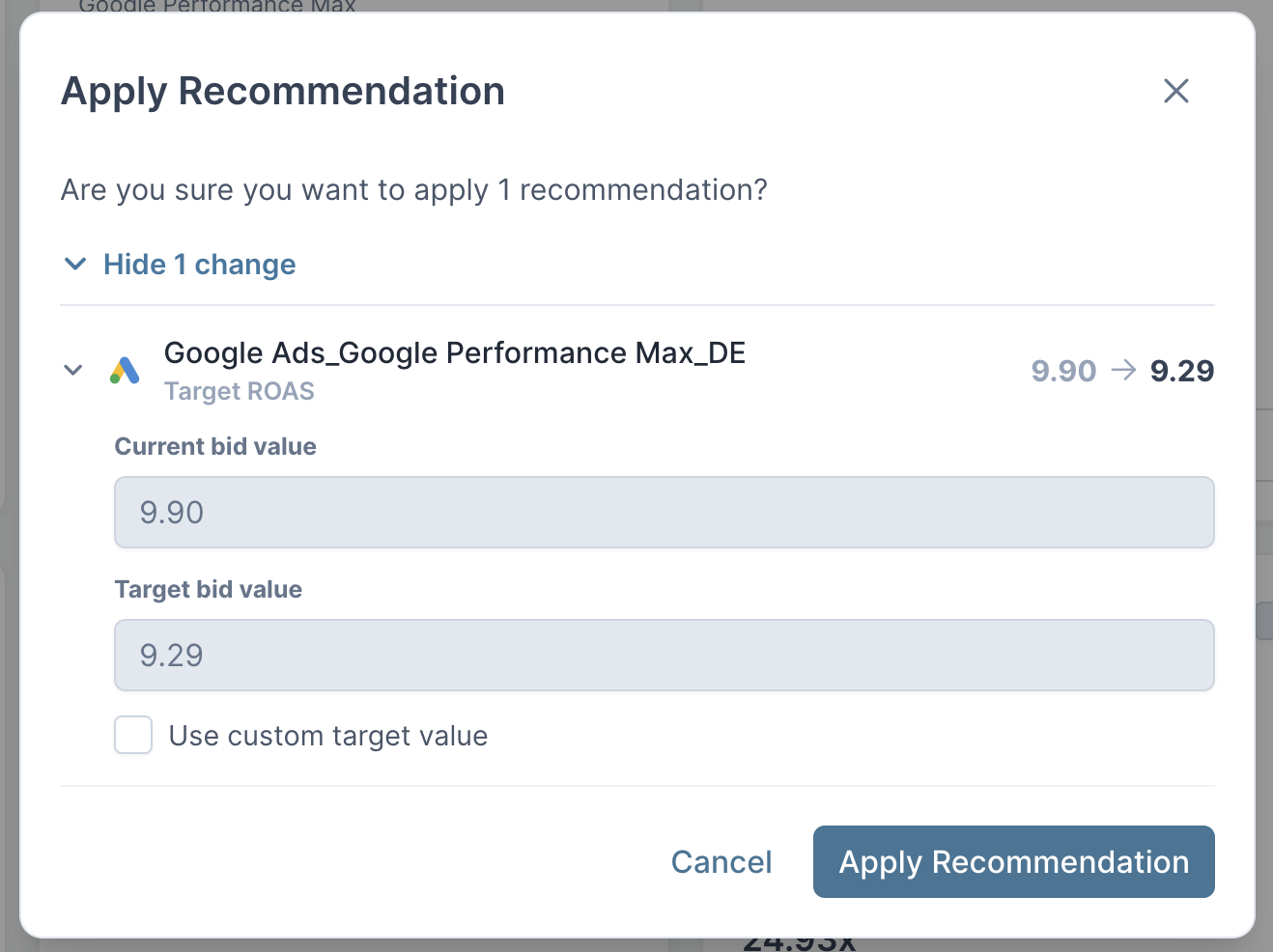
Category 7. AI's UX & Conversational Interface
This category measures AI tools' user-experience and features available in the conversational chat interface.
Tested features in this category include chat history, context retention, ability to provide inline tables and charts, multi-window mode, and exportable outputs (PDF, Slides, CSV). We also test features building trust, such as ability to provide reasoning flow and links from AI answers to source data and deep-dive dashboards.
To illustrate reasoning flows in action, below is a screenshot from a Sellforte describing its interpretation of a user prompt as well as steps its taking to reply to it.
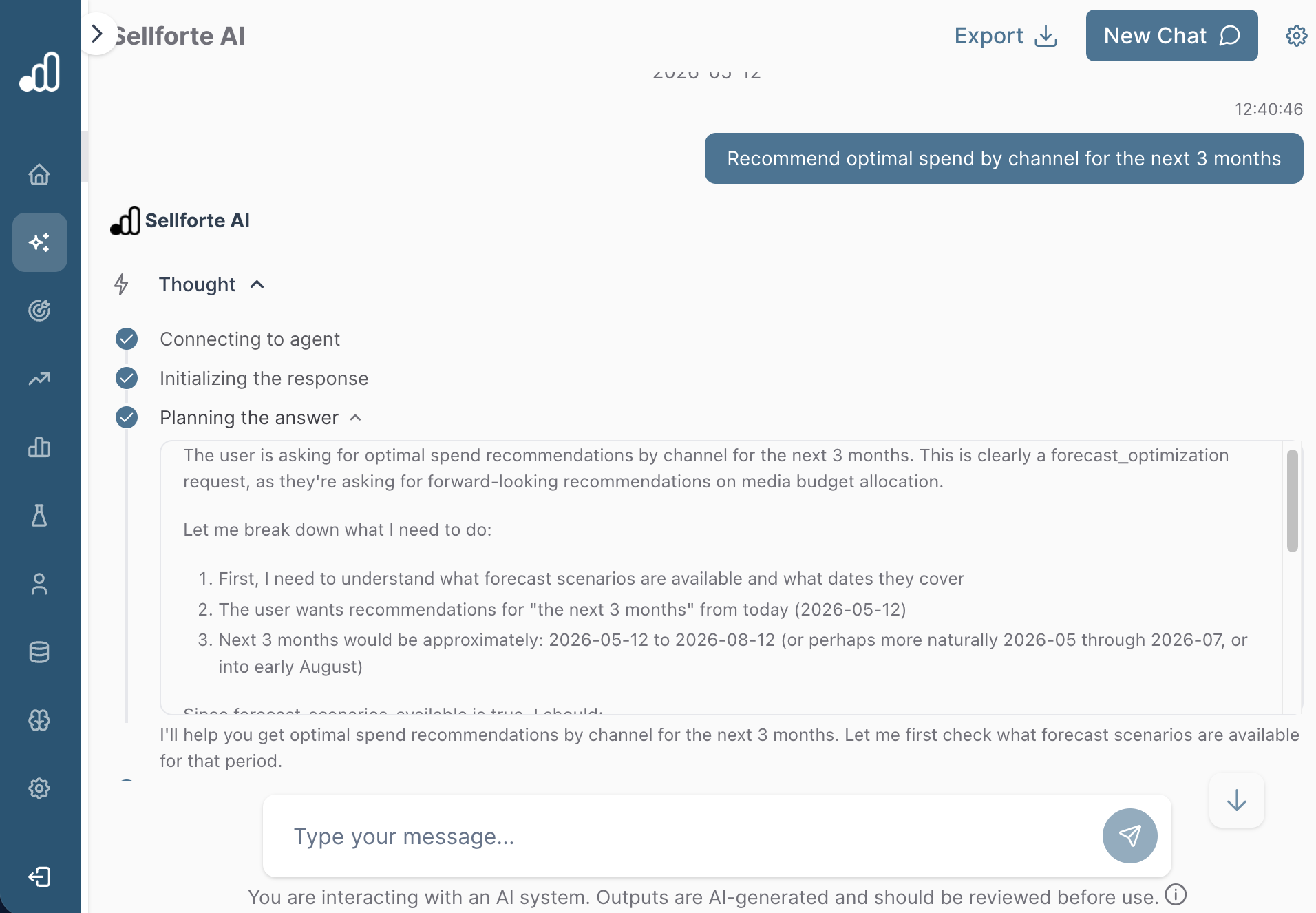
To illustrate a dual-window mode in action, below is a screenshot from Sellforte where AI interface is next to a budget optimizer tool. The AI on the right side of the screen can be asked to use the optimizer to find optimal budget allocations, and the user can continue scenario configuration in a manual mode on the left side of the screen if needed.
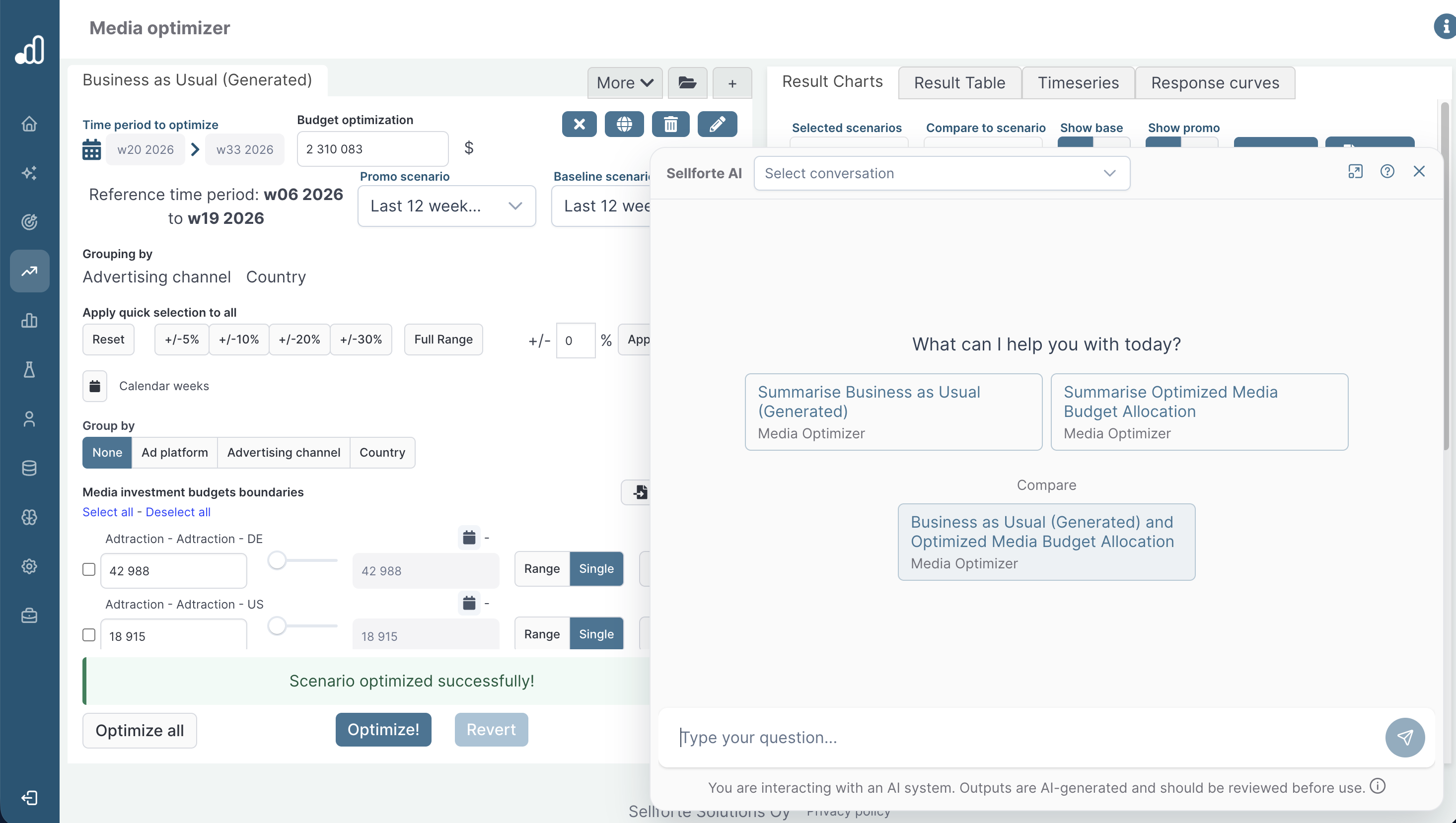
Category 8. Analytical Backbone of the Conversational AI
Everything in the previous categories measured what the AI does. This category is about what the AI is built on.
Modern marketing measurement and optimisation systems are built on three core methodologies: Marketing Mix Modeling, incrementality testing and attribution, as illustrated in the chart below.
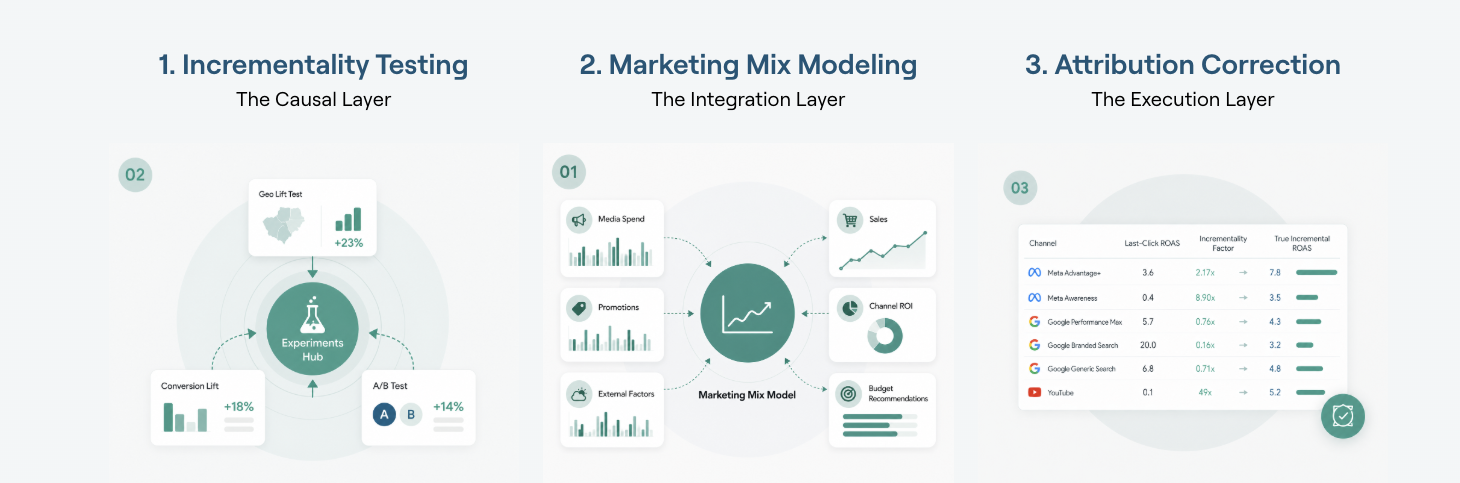
Evaluate criteria include whether the AI tool for MMM and Incrementality Testing is powered by a Bayesian Marketing Mix Model calibrated with incrementality tests, whether model validation features are available, and whether there are transparent model configuration and calibration tools available for the user.
Category 9. Enterprise-grade platform
This final category measures whether the AI tools can operate in an enterprise environment, serving large organizations with mature IT policies.
The dimensions scored include large client references, security certifications (SOC 2, ISO 27001), data residency options between US and EU regions, multi-cloud support across AWS, GCP, and Azure, and enterprise authentication via single sign-on.
While mid-sized brands might not yet express all of these requirements, they will ultimately grow into a size where such requirements become not just relevant but mandatory for procurement approval.
What biases & limitations does our evaluation criteria have, and how are we addressing them?
Bias 1: Industry sample bias toward Ecommerce and Retail. The 1,660 prompts and 700+ customer discussions that informed the criteria come predominantly from Sellforte's customer and prospect base, which skews heavily toward Retail and Ecommerce. This means certain use cases that might matter more in other verticals, such as brand measurement in CPG/FMCG may be underrepresented.
Bias 2: Coverage of requirements from both small and large businesses. The criteria span a wide range, from table-stakes capabilities that even small ecommerce brands need (basic data reporting, channel-level optimization) to enterprise-grade requirements (multi-cloud, SSO, EU data residency, $1B+ customer references). This breadth is intentional but means no single vendor scores perfectly: a tool purpose-built for SMBs will be penalized on enterprise criteria it has no reason to meet, and vice versa. We address this partially through the "Best for" summaries for each vendor, which contextualize the scores against the buyer segment each tool is designed for.
Research Methodology: Scoring
Scoring each tool against the evaluation criteria was done by Claude (Opus 4.8 with High Effort) and ChatGPT (5.5 Pro). Here were the assessment steps:
Step 1. Both LLMs independently scored each criterion for each vendor, based on the instructions in this section.
Step 2. For the final score for each criteria, we used an average between the two LLMs, rounded to 1 decimal.
Step 3. Category scores were created by summing up the scores from each criteria in the category, and total score was calculated by by summing up the category scores.
Why is the scoring done by Claude and ChatGPT?
Simulating evaluation a buyer might make based on public materials. By using only vendor-provided materials on their website and technical documentation in the assessment, Claude and ChatGPT -based evaluation simulates how a buyer without prior knowledge of the vendor might assess the vendor prior to a sales call or demo meeting.
Minimizing vendor bias. A common challenge in tool and vendor evaluations is the conscious or unconscious bias that the evaluator might have in assigning scores. This is especially challenging in research where the company represented by the evaluator is part of the evaluation. Even if the evaluator does their best to manage bias, a conflict of interest can leave doubts in the reader's mind. Outsourcing the evaluation to Claude and ChatGPT removes human biases in the evaluation.
Transparent methodology and reproducible assessment. Because the evaluation instructions are published alongside this article, any reader can re-run the evaluation for any vendor and verify or challenge the results. This is a higher standard of transparency than conventional analyst-style research, where the scoring rationale is typically not disclosed.
Vendors with equal opportunity to affect scoring. Because scoring is driven by publicly available documentation, every vendor has the same opportunity to influence their scores. No vendor benefits from being better known to the evaluator.
Equal treatment of vendors. Claude and ChatGPT apply the same instructions, the same criteria, the same scoring scale, and the same source prioritization rules to every vendor in the comparison.
LMS have higher capacity to discover published materials than humans manually. LLMs with web search can systematically scan a vendor's website, support center, technical documentation, and marketing collateral in a way that would take a human researcher significantly longer. This increases the likelihood that relevant evidence is found and reduces the risk of penalizing a vendor for documentation the evaluator simply did not locate.
Instructions given to Claude and ChatGPT
The following table contains the complete set of instructions provided to both models for each vendor evaluation. These instructions are also available as a Google Sheet: Evaluation instructions: Conversational AI Tools for MMM and Incrementality Testing.
| Instruction ID | Instruction |
|---|---|
| 1 | Act as an independent evaluator of Conversational AI tools for Marketing Mix Modeling and Incrementality Testing. |
| 2 | Use evaluation criteria from the Criteria sheet. |
| 3 | In the evaluation, only use information available at the company website, and in the domain where technical documentation is located (if separately hosted). |
| 4 | When scoring categories 1–6, use the scoring model from the Scoring — Cat 1–6 sheet. |
| 5 | When scoring categories 7–9, use the scoring model from the Scoring — Cat 7–9 sheet. |
| 6 | When scoring category 1, you can assume a score of 1 if you find evidence of the overall platform supporting the capability. |
| 7 | When scoring criteria 2.1, 2.2, and 2.3, you can assume a score of 1 if you find evidence of the overall platform supporting the capability. |
| 8 | If you find evidence that the conversational AI supports optimization of offline media, you can assume that the tool also measures offline media iROAS. |
| 9 | If you find evidence that the conversational AI supports optimization of digital media, you can assume that the tool also measures digital media iROAS. |
| 10 | When interpreting terminology, you can assume that - ROI is the same thing as incremental ROAS - Marginal ROI is the same thing as Marginal Incremental ROAS or miROAS - Diminishing return curves are the same thing as response curves |
| 11 | A vendor's conversational AI (a first-party chat the vendor built into its product) is a separate surface from an MCP server. MCP availability proves the underlying capability exists, so it can support the "broader platform" scoring, but it never earns the top "in conversational AI chat" tiers (1 / 0.75) unless the vendor demonstrates the capability inside its own first-party AI chat. |
| 12 | Prioritize source materials in this order: 1. Technical documentation (such as a support center); 2. Product page; 3. Marketing collateral (such as product launch blog posts). |
| 13 | As an output, provide your evaluation in an excel file, using these columns: - Category Number - Category ID - Criteria Score - Two-sentence rationale for the score. If you found no evidence, comment that you did not find evidence, instead of claiming that the capability does not exist - URL to source - Type of source |
Let's next discuss the instructions in detail.
Scoring model for Categories 1–6 (Instruction 4)
In instruction 4, we asked the LLMs to use the scoring table below for categories 1 through 6.
| Score | Definition |
|---|---|
| 1.0 | Strong public evidence that the capability exists in the conversational AI chat interface |
| 0.75 | Partial public evidence that the capability exists in the conversational AI chat interface |
| 0.5 | Feature is not available via the conversational chat interface, but there is strong public evidence that the capability is available in the broader platform |
| 0.25 | Feature is not available via the conversational chat interface, but there is partial public evidence the capability is available in the broader platform |
| 0.0 | No evidence found that the feature exists in the conversational AI tool or in the broader platform |
Categories 1 through 6 cover functional capabilities of the conversational AI. For these categories, the scoring model distinguishes between capabilities demonstrated inside the vendor's conversational AI chat interface versus capabilities only evidenced in the broader platform.
We are instructing the LLMs to assign scores 1 or 0.75 if there is evidence (strong or partial) that a feature is available in the Conversational AI interface.
We asked the LLMs to give a score of 0.5 or 0.25 if there is a capability that exists in the platform, but there is no evidence for it being available via the Conversational AI interface. As an example, a platform might be able to show geo test results, but there is no documentation where the AI can summarize their findings. Why did we apply this instruction? We wanted each of the assessed platform get some credit in these cases as well for two reasons. Firstly, it is likely that the feature will be added to conversational AI in the near future. Secondly, it is possible that the feature can already be accessed via the conversational AI, but the documentation does not yet exist.
A score of 0 means the LLMs could not verify a capability from public sources, not that the capability does not exist.
Scoring model for Categories 7–9 (Instruction 5)
In instruction 5, we asked the LLMs to use the scoring table below for categories 7 through 9.
| Score | Definition |
|---|---|
| 1.0 | Strong evidence that the platform supports the capability |
| 0.5 | Partial evidence that the platform supports the capability |
| 0.0 | No evidence found that the platform supports the capability |
Categories 7 through 9 cover the conversational interface UX, the analytical backbone of the AI, and the enterprise platform maturity.
For these categories, we instructed LLMs to assign 1 if there is strong evidence that the platform supports the capability and 0.5 if there the evidence is partial but not strong.
A score of 0 means the LLMs could not verify a capability from public sources, not that the capability does not exist.
Scoring Instructions 3 and 12: Source material
Instruction 3: "In the evaluation, only use information available at the company website, and in the domain where technical documentation is located (if separately hosted)."
This constraint keeps the playing field level. Every vendor controls the source material used for assessing their capabilities, and thus every vendor has the same opportunity to influence their scores.
Instruction 12: "Prioritize type of source materials in this order: 1. Technical documentation (such as a support center); 2. Product page; 3. Marketing collateral (such as product launch blog posts)."
Technical documentation is prioritized because it is typically the most precise and the least subject to marketing inflation. Product pages on vendors' website are second, as they also tend to be feature-driven. Marketing collateral, such product launch blog posts are treated as third type of evidence.
Scoring Instructions 6, 7, 8, 9: Assuming basic features
We noticed that vendors' documentation is sometimes focused on the most advanced features of the tools, and the basic features might not be fully spelled out. This is the case especially with vendors who have relatively little focus on public documentation. For this reason, we decided to ask the LLMs to make assumptions that some of the basic features, such as data reporting, exist in the conversational AI, if there's evidence for the overall platform supporting them.
Instruction 6: "When scoring category 1, you can assume a score of 1 if you find evidence of the overall platform supporting the capability."
Instruction 7: "When scoring criteria 2.1, 2.2, and 2.3, you can assume a score of 1 if you find evidence of the overall platform supporting the capability."
The criteria referenced in instructions 6 and 7 cover the most basic data reporting capabilities, such as does the Conversational AI give access to digital media data, or does it report the iROAS / ROI of digital channels. We asked the LLMs to assume they exist in the conversational AI if there was evidence that that broader platform covers it.
Instruction 8: "If you find evidence that the conversational AI supports optimization of offline media, you can assume that the tool also measures offline media iROAS"
Instruction 9: "If you find evidence that the conversational AI supports optimization of digital media, you can assume that the tool also measures digital media iROAS"
These instructions are also related to the existence of basic features. If the LLMs found evidence that digital media spend could be optimized with AI, we asked them to assume that basic measurement of digital iROAS / ROI also existed.
Disclaimer: Instructions 6, 7, 8 and 9 benefit most vendors whose documentation is limited, and is less beneficial for vendors with extensive documentation.
Scoring Instruction 10: Terminology
Instruction 10: "When interpreting terminology, you can assume that
- ROI is the same thing as incremental ROAS
- Marginal ROI is the same thing as Marginal Incremental ROAS or miROAS
- Diminishing return curves are the same thing as response curves"
Different vendors use different terminology for the same underlying concepts. Penalizing a vendor for calling it "Marginal ROI" instead of "miROAS" would introduce scoring noise unrelated to actual capability differences. These equivalences make terminology interpretation consistent across all vendors.
Scoring Instruction 11: Focus on Conversational AI
Instruction 11: "A vendor's conversational AI (a first-party chat the vendor built into its product) is a separate surface from an MCP server. MCP availability proves the underlying capability exists, so it can support the "broader platform" scoring, but it never earns the top "in conversational AI chat" tiers (1 / 0.75) unless the vendor demonstrates the capability inside its own first-party AI chat."
This is one of the most important methodological choices in the evaluation. An MCP server lets an external LLM query a vendor's data, but that is not the same as the vendor's own AI chat interface answering a question. A marketer asking "what was my incremental ROAS on Meta last month?" in a vendor's first-party AI is having a different product experience than a developer who has wired up an external Claude instance to the same vendor's MCP. Both matter, but they are distinct product surfaces, and this evaluation focuses on the first-party conversational AI experience. We might do a separate evaluation of MCPs, as the space develops.
How to interpret the scores?
The scoring framework that the LLMs were asked to use is specifically targeted to evaluate availability of public evidence for the capabilities, and thus it should be interpreted as such. There might be a gap between actual features of the platform and what's publicly documented by the vendors.
How to reproduce the evaluation and scoring yourself with Claude or ChatGPT?
To reproduce the evaluation for any vendor in this study, you can follow the instructions in this section. They are accurate as of 10th June 2026, and might require changes as Claude and ChatGPT amend their features.
Step 1. Download the Evaluation Instructions Google Sheet as an Excel file (or other file format you can attach to an LLM prompt): Evaluation instructions: Conversational AI Tools for MMM and Incrementality Testing. We could not get LLMs to access the Google Sheet directly without a Google Drive integration.
Step 2. Open Claude in Incognito mode to disconnect its memory about your previous conversations that might influence the evaluation. To achieve the same in ChatGPT, you need to disable ChatGPT memory.
Step 3. Choose a model. We used Opus 4.8 with High Effort and ChatGPT 5.5 Pro to maximize the LLMs' capabilities to discover vendor content and use it to evaluate the vendors.
Step 4. Initiate the prompt: "Evaluate [add vendor name, e.g., Sellforte], based on the instructions in the attached Excel."
Note: Model names and availability accurate as of June 2026. Reproducibility instructions may require updating as model versions change.
Future updates of scoring
This comparison is updated on a rolling basis, with a full refresh targeted at least once per quarter.
What biases & limitations does our scoring approach have, and how are we addressing them?
While LLM-based evaluation reduces vendor bias and promotes equal treatment of vendors and reproducibility, there are four main limitations to be aware of.
1. Availability and of documentation that each vendor has made public. A vendor with extensive and detailed public documentation will naturally score higher than one that keeps product details behind a sales call gate, even if the underlying capabilities are comparable. Each vendor can affect their own scoring through public documentation.
2. LLMs' ability to find public documentation. Even with web search enabled, Claude and ChatGPT may not find every relevant page on a vendor's website. Documentation that is not well-indexed or that sits in obscure subdomains may be missed. We tried to address this by using advanced models from two separate LLMs, and added a specific point to the instructions to search for vendor-provided technical documentation that might sometimes be under a different sub-domain.
3. LLMs' ability to interpret public documentation against the scoring criteria. Matching a product description to a specific criterion requires judgment. We reduce interpretation variance by using advanced models from two separate LLMs, providing detailed criterion descriptions, and providing explicit terminology equivalences (instruction 10.0). However, edge cases may still exist.
4. Limitations of LLM technology, including hallucinations. LLMs are known to occasionally assert things that are not based on facts. To reduce this risk, we used advanced models from two separate LLMs, asked them to provide source URL for their assessment, and asked them to provide a rationale for the score in each criterion.
What tools we evaluated: Conversational AI tools for MMM and Incrementality Testing
We focused this article on conversational AI tools for MMM and Incrementality Testing that meet all three of the following criteria:
- Real product: Proven AI tool with a conversational interface for MMM and Incrementality Testing that is offered as a dedicated tool or as part of a broader measurement platform.
- Used by recognized advertisers: The tool is used in production by enterprise brands, with at least some publicly verifiable customer references.
- Recognized by the industry: The tool has visible market presence, including coverage in industry press, analyst reports, social media discussion, or conference talks.
When searching for tools that would meet these criteria we looked into multiple product categories: Data connector companies, traditional Marketing Mix Modeling providers, next gen MMM vendors, Incrementality testing tools, attribution tools and generic AI tools. Surprisingly, we found out that AI adoption is still low in many of these categories. As an example, we found out that only 13% of Marketing Mix Modeling vendors have implemented AI. Based on public documentation, we could not find conversational AI tools from Many notable MMM players, such as Measured, Recast, Paramark, Incrmntal, Keen Decision Systems and Prescient AI.
For the first analysis batch, we evaluated five AI tools for MMM and Incrementality Testing matching the criteria above: Sellforte, Triple Whale, Mutinex, Lifesight and Fospha.
We are updating this article with additional vendors during 2026, as new AI tools are introduced.
In-depth Comparison of Conversational AI tools for MMM and Incrementality Testing
The table below shows the detailed in-depth comparison of Conversational AI tools for MMM and Incrementality Testing. Additionally, the full assessment created by Claude and ChatGPT is available in this Google Sheet: Evaluation: Conversational AI Tools for MMM and Incrementality Testing .
| Category | Criterion | Sellforte | Lifesight | Triple Whale | Fospha | Mutinex |
|---|---|---|---|---|---|---|
| 1. Marketing Data Reporting via conversational AI | ||||||
| 1. Marketing Data Reporting via conversational AI | 1.1 AI reports sales progress for online sales | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 1.2 AI reports sales progress for offline store sales | 1.0 | 1.0 | 0.6 | 0.0 | 1.0 | |
| 1.3 AI reports digital media data (spend, impressions, clicks) | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | |
| 1.4 AI reports offline media data | 1.0 | 1.0 | 1.0 | 0.1 | 1.0 | |
| 2. Historical Performance Insights & Causal Explanation via conversational AI | ||||||
| 2. Historical Performance Insights & Causal Explanation via conversational AI | 2.1 AI measures incremental ROAS and incremental revenue for each digital channel | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 2.2 AI measures incremental ROAS and incremental revenue for each offline channel | 1.0 | 1.0 | 1.0 | 0.1 | 1.0 | |
| 2.3 AI reports promotion-driven revenue, in addition to media-driven | 1.0 | 1.0 | 1.0 | 0.3 | 1.0 | |
| 2.4 AI-reported incremental ROAS is updated daily | 0.8 | 0.5 | 0.3 | 1.0 | 0.4 | |
| 2.5 AI explains why performance has changed | 0.9 | 0.9 | 1.0 | 1.0 | 1.0 | |
| 3. Channel-Level Optimization with conversational AI | ||||||
| 3. Channel-Level Optimization with conversational AI | 3.1 AI recommends optimal budget allocation by channel | 1.0 | 1.0 | 0.8 | 0.6 | 1.0 |
| 3.2 AI forecasts total revenue based on optimal budget allocation | 1.0 | 0.9 | 0.6 | 0.5 | 1.0 | |
| 3.3 AI provides miROAS and response curves for each channel | 0.8 | 0.9 | 0.5 | 0.5 | 0.8 | |
| 3.4 AI supports basic custom scenario planning (e.g., "what if I cut Meta by 20%?") | 0.9 | 1.0 | 0.6 | 0.5 | 1.0 | |
| 3.5 AI supports advanced scenario planning in natural language (constraints, multi-dimensional optimization…) | 0.8 | 0.9 | 0.5 | 0.4 | 0.8 | |
| 4. Campaign & Ad Set-Level Optimization for Digital Channels with conversational AI | ||||||
| 4. Campaign & Ad Set-Level Optimization for Digital Channels with conversational AI | 4.1 AI provides incremental ROAS of each campaign & ad set | 0.8 | 0.5 | 0.5 | 0.6 | 0.8 |
| 4.2 AI compares incremental ROAS to last-click and ad platform attribution ROAS | 0.5 | 0.5 | 0.5 | 0.5 | 0.0 | |
| 4.3 AI provides miROAS for each campaign & ad set | 0.9 | 0.3 | 0.3 | 0.3 | 0.0 | |
| 4.4 AI recommends optimal spend for each campaign & ad set | 0.9 | 0.5 | 0.8 | 0.5 | 0.3 | |
| 4.5 AI recommends optimal bid value for each campaign & ad set | 0.9 | 0.4 | 0.5 | 0.1 | 0.0 | |
| 4.6 AI provides pre/post analysis for each bidding change | 0.5 | 0.3 | 0.3 | 0.5 | 0.0 | |
| 5. Incrementality Testing with conversational AI | ||||||
| 5. Incrementality Testing with conversational AI | 5.1 AI can summarize results for Geo Tests | 1.0 | 0.6 | 0.8 | 0.1 | 0.0 |
| 5.2 AI can summarize results for Own Media A/B tests (e.g. leaflet tests) | 0.8 | 0.4 | 0.0 | 0.0 | 0.0 | |
| 5.3 Platform ingests Meta Conversion Lift tests and AI summarizes findings | 1.0 | 0.0 | 0.8 | 0.1 | 0.0 | |
| 5.4 AI provides incrementality testing recommendations | 0.8 | 0.8 | 0.9 | 0.1 | 0.1 | |
| 5.5 AI provides incrementality test design recommendations | 0.8 | 0.8 | 0.5 | 0.1 | 0.0 | |
| 6. Agentic Execution & Autonomy | ||||||
| 6. Agentic Execution & Autonomy | 6.1 AI can push daily spend/budget changes to Meta, Google, TikTok APIs | 0.8 | 0.8 | 1.0 | 0.5 | 0.0 |
| 6.2 AI can push bidding changes (e.g., Target ROAS) to Meta, Google, TikTok APIs | 0.8 | 0.4 | 0.9 | 0.1 | 0.0 | |
| 6.3 AI's level of autonomy for execution can be configured | 0.5 | 0.9 | 1.0 | 0.5 | 0.0 | |
| 6.4 Proactive insights & alerts via AI | 0.1 | 0.8 | 1.0 | 0.5 | 0.1 | |
| 7. AI's UX & Conversational Interface | ||||||
| 7. AI's UX & Conversational Interface | 7.1 Includes tables and charts inline in AI responses | 1.0 | 0.5 | 1.0 | 0.8 | 1.0 |
| 7.2 AI has conversation history & multi-turn context retention | 0.5 | 0.5 | 1.0 | 1.0 | 1.0 | |
| 7.3 Allows convenient export of AI outputs (e.g., PDF, Slides, CSV) | 0.5 | 0.5 | 0.8 | 0.8 | 1.0 | |
| 7.4 AI grounds answers in data, providing links from outputs to deep-dive dashboards | 0.0 | 0.5 | 0.8 | 1.0 | 0.0 | |
| 7.5 AI operates in embedded and multi-window mode (chat + dashboard side-by-side) | 0.5 | 0.3 | 0.8 | 0.8 | 0.8 | |
| 7.6 AI shows its reasoning steps and logic while answering | 0.8 | 1.0 | 0.8 | 0.5 | 0.3 | |
| 7.7 AI handles non-English questions in production | 0.3 | 0.3 | 0.5 | 0.8 | 0.0 | |
| 7.8 AI can be accessed via MCP server / external LLM | 0.0 | 1.0 | 1.0 | 1.0 | 0.0 | |
| 8. Analytical Backbone of the Conversational AI | ||||||
| 8. Analytical Backbone of the Conversational AI | 8.1 AI provides deterministic, model-backed answers with Bayesian MMM as backbone | 1.0 | 0.5 | 0.5 | 0.8 | 1.0 |
| 8.2 Bayesian MMM used by the AI is calibrated with incrementality tests | 1.0 | 0.8 | 0.8 | 0.5 | 0.5 | |
| 8.3 AI reports model validation and other modelling KPIs | 1.0 | 1.0 | 0.8 | 1.0 | 0.8 | |
| 8.4 Model calibration & configuration settings (e.g., priors) are auditable and editable in a self-serve UI | 0.5 | 0.8 | 1.0 | 0.5 | 0.0 | |
| 9. Enterprise-Grade Platform | ||||||
| 9. Enterprise-Grade Platform | 9.1 At least 10 public reference customers from $1B+ revenue brands | 0.8 | 1.0 | 0.3 | 0.8 | 1.0 |
| 9.2 SOC 2, ISO 27001, or audited IT security by a third-party cyber security auditor | 1.0 | 1.0 | 1.0 | 0.5 | 1.0 | |
| 9.3 Data residency: geography option between US and EU | 0.5 | 1.0 | 0.0 | 0.8 | 0.0 | |
| 9.4 Multi-cloud: option between AWS, GCP, and Azure | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | |
| 9.5 Supports single sign-on (SSO) for enterprises | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | |
| 9.6 Customer data is not shared to a third-party LLM (LLM deployed in customer-specific cloud container) | 0.3 | 0.8 | 0.0 | 0.3 | 1.0 | |
| 9.7 Hands-on demo or trial of the AI is available without sales-call gating | 1.0 | 0.3 | 0.5 | 0.0 | 0.0 | |
| Total out of 48 | 36.3 | 33.1 | 32.6 | 25.1 | 24.4 | |
1. Sellforte (scoring 36.3 out of 48): Enterprise-grade AI tool for Channel and Campaign-level optimization
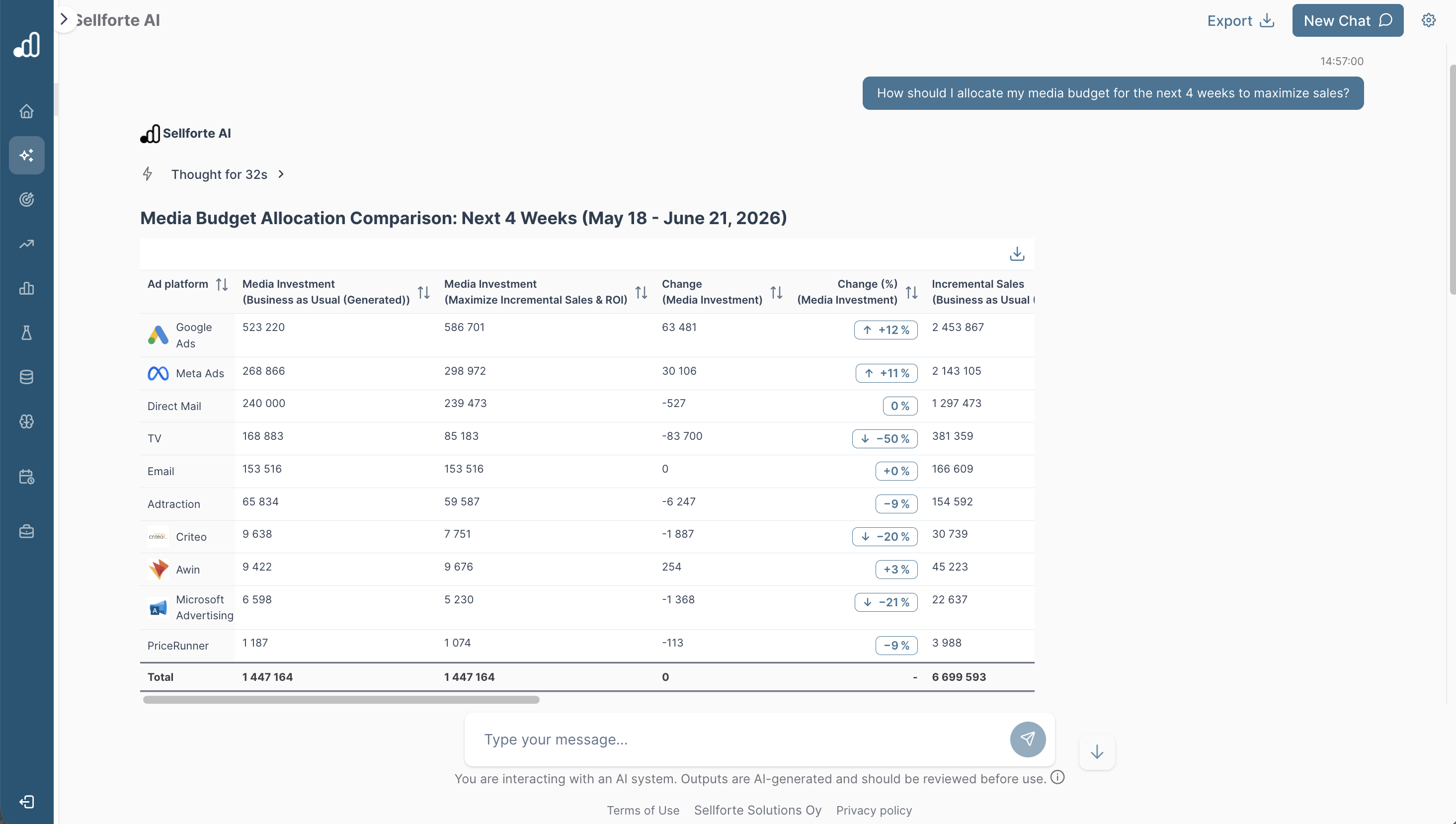
Overview
Sellforte is an enterprise-grade AI tool for marketing teams, supporting channel- and campaign-level media spend optimization, grounded in Sellforte's analytical backbone covering MMM, incrementality testing and incrementality-corrected attribution.
Sellforte scores 36.3 out of 48, placing it first in this comparison. While performing well in most assessed categories, its main differentiators are campaign and ad set level optimization and incrementality testing through the conversational AI, providing advertisers with spend and bidding recommendations for each campaign and ad set that can be executed on the ad platforms. Sellforte's main limitations are a lower-scoring conversational interface UX and the absence of public evidence for an MCP server for external LLM access.
Evaluation summary
| Category | Sellforte |
|---|---|
| 1. Marketing Data Reporting via conversational AI | 4.0 / 4 |
| 2. Historical Performance Insights & Causal Explanation via conversational AI | 4.6 / 5 |
| 3. Channel-Level Optimization with conversational AI | 4.4 / 5 |
| 4. Campaign & Ad Set-Level Optimization for Digital Channels with conversational AI | 4.4 / 6 |
| 5. Incrementality Testing with conversational AI | 4.3 / 5 |
| 6. Agentic Execution & Autonomy | 2.1 / 4 |
| 7. AI's UX & Conversational Interface | 3.5 / 8 |
| 8. Analytical Backbone of the Conversational AI | 3.5 / 4 |
| 9. Enterprise-Grade Platform | 5.5 / 7 |
| Total score out of 48 | 36.3 |
Scoring reflects evidence found by Claude and ChatGPT in publicly available documentation as of June 2026. A score of 0 does not indicate the capability is absent.
Strengths: Categories with highest scores in this research
-
Campaign and ad set-level optimization for digital channels via conversational AI. Sellforte scores 4.4 / 6 in this category.
-
Incrementality testing via conversational AI. Sellforte scores 4.3 / 5 in this category.
-
Enterprise-grade platform. Sellforte scores 5.5 / 7 in this category.
Limitations: Categories with lowest scores in this research
-
Agentic execution and autonomy. Sellforte scores 2.1 / 4 in this category.
-
AI's UX and conversational interface. Sellforte scores 3.5 / 8 in this category.
Notable Reference Customers
Sellforte lists following companies as examples of public reference customers:
- Fashion Ecommerce: bonprix, Azzas 2154, Represent, Odlo
- Home & Furniture Ecommerce: Finnish Design Shop
- Specialty Ecommerce: FCP Euro, Smartphoto, Caseking
- Grocery Retail: Lidl
- Fashion Retail: C&A, KIK
- Cosmetics Retail: Douglas
- Sport Retail: Intersport
- Pet Retail: Fressnapf, Musti Group
- Specialty Retail: Tchibo
- Electronics Retail: Verkkokauppa.com
- Other segments: Telenor (Telecommunications), Paysafe (Payments), eBilet (part of Allegro Group, Events)
Best for
Sellforte is best for marketing teams looking for an enterprise-grade AI tool that supports channel- and campaign-level media spend optimization, grounded in analytical backbone covering MMM, incrementality testing and incrementality-corrected attribution. Sellforte is particularly strong in Retail and Ecommerce.
2. Lifesight (scoring 33.1 out of 48)
Overview
Lifesight provides a conversational AI, called Lifesight MIA, on top of Lifesight's Unified Measurement OS, which covers MMM and geo lift tests.
Evaluation summary
| Category | Lifesight |
|---|---|
| 1. Marketing Data Reporting via conversational AI | 4.0 / 4 |
| 2. Historical Performance Insights & Causal Explanation via conversational AI | 4.4 / 5 |
| 3. Channel-Level Optimization with conversational AI | 4.6 / 5 |
| 4. Campaign & Ad Set-Level Optimization for Digital Channels with conversational AI | 2.4 / 6 |
| 5. Incrementality Testing with conversational AI | 2.5 / 5 |
| 6. Agentic Execution & Autonomy | 2.8 / 4 |
| 7. AI's UX & Conversational Interface | 4.5 / 8 |
| 8. Analytical Backbone of the Conversational AI | 3.0 / 4 |
| 9. Enterprise-Grade Platform | 5.0 / 7 |
| Total score out of 48 | 33.1 |
Scoring reflects evidence found by Claude and ChatGPT in publicly available documentation as of June 2026. A score of 0 means the LLMs could not verify a capability from public sources, not that the capability does not exist.
Strengths: Categories with highest scores in this research
-
Channel-level optimization via conversational AI. Lifesight scores 4.6 / 5 in this category.
-
Historical performance insights and causal explanation via conversational AI. Lifesight scores 4.4 / 5 in this category.
-
Enterprise-grade platform. Lifesight scores 5.0 / 7 in this category.
Limitations: Categories with lowest scores in this research
-
Campaign and ad set-level optimization for digital channels via conversational AI. Lifesight scores 2.4 / 6 in this category.
-
Incrementality testing via conversational AI. Lifesight scores 2.5 / 5 in this category.
Best for
Lifesight is best for ecommerce and consumer brand marketers requiring a conversational AI for media spend optimization based on Lifesight's analytics, but for whom full incrementality test coverage is not a priority.
3. Triple Whale (scoring 32.6 out of 48)
Overview
Triple Whale provides a conversational AI built primarily for small and mid-sized ecommerce and DTC brands, with its AI tool named Moby AI.
Evaluation summary
| Category | Triple Whale |
|---|---|
| 1. Marketing Data Reporting via conversational AI | 3.6 / 4 |
| 2. Historical Performance Insights & Causal Explanation via conversational AI | 4.3 / 5 |
| 3. Channel-Level Optimization with conversational AI | 3.0 / 5 |
| 4. Campaign & Ad Set-Level Optimization for Digital Channels with conversational AI | 2.8 / 6 |
| 5. Incrementality Testing with conversational AI | 2.9 / 5 |
| 6. Agentic Execution & Autonomy | 3.9 / 4 |
| 7. AI's UX & Conversational Interface | 6.5 / 8 |
| 8. Analytical Backbone of the Conversational AI | 3.0 / 4 |
| 9. Enterprise-Grade Platform | 2.8 / 7 |
| Total score out of 48 | 32.6 |
Scoring reflects evidence found by Claude and ChatGPT in publicly available documentation as of June 2026. A score of 0 means the LLMs could not verify a capability from public sources, not that the capability does not exist.
Strengths: Categories with highest scores in this research
-
Agentic execution and autonomy. Triple Whale scores 3.9 / 4 in this category.
-
AI's UX and conversational interface. Triple Whale scores 6.5 / 8 in this category.
-
Historical performance insights and causal explanation via conversational AI. Triple Whale scores 4.3 / 5 in this category.
Limitations: Categories with lowest scores in this research
-
Enterprise-grade platform. Triple Whale scores 2.8 / 7 in this category.
-
Campaign and ad set-level optimization for digital channels via conversational AI. Triple Whale scores 2.8 / 6 in this category.
-
Channel-level optimization via conversational AI. Triple Whale scores 3.0 / 5 in this category.
Best for
Triple Whale is best for small and mid-sized ecommerce businesses requiring a strong AI tool, but for whom incrementality-based optimization at the campaign and ad set level and enterprise-grade MMM is not a priority.
4. Fospha (scoring 25.1 out of 48)
Overview
Fospha provides a conversational AI on top of Fospha's measurement platform, which covers MTA and Bayesian MMM. Fospha is positioned for DTC and consumer brands.
Evaluation summary
| Category | Fospha |
|---|---|
| 1. Marketing Data Reporting via conversational AI | 2.1 / 4 |
| 2. Historical Performance Insights & Causal Explanation via conversational AI | 3.4 / 5 |
| 3. Channel-Level Optimization with conversational AI | 2.5 / 5 |
| 4. Campaign & Ad Set-Level Optimization for Digital Channels with conversational AI | 2.5 / 6 |
| 5. Incrementality Testing with conversational AI | 0.5 / 5 |
| 6. Agentic Execution & Autonomy | 1.6 / 4 |
| 7. AI's UX & Conversational Interface | 6.5 / 8 |
| 8. Analytical Backbone of the Conversational AI | 2.8 / 4 |
| 9. Enterprise-Grade Platform | 3.3 / 7 |
| Total score out of 48 | 25.1 |
Scoring reflects evidence found by Claude and ChatGPT in publicly available documentation as of June 2026. A score of 0 means the LLMs could not verify a capability from public sources, not that the capability does not exist.
Strengths: Categories with highest scores in this research
-
AI's UX and conversational interface. Fospha scores 6.5 / 8 in this category.
-
Historical performance insights and causal explanation via conversational AI. Fospha scores 3.4 / 5 in this category.
-
Marketing data reporting via conversational AI. Fospha scores 2.1 / 4 in this category.
Limitations: Categories with lowest scores in this research
-
Incrementality testing via conversational AI. Fospha scores 0.5 / 5 in this category.
-
Channel-level optimization via conversational AI. Fospha scores 2.5 / 5 in this category.
-
Campaign and ad set-level optimization for digital channels via conversational AI. Fospha scores 2.5 / 6 in this category.
Best for
Fospha is best for small ecommerce businesses requiring conversational AI for historical performance reporting, but for whom future-looking optimization and enterprise-grade measurement platform covering also causal experimentation is not a priority.
5. Mutinex (scoring 24.4 out of 48)
Overview
Mutinex provides a conversational AI, called MAITE, which is built on top of Mutinex's GrowthOS MMM platform.
Evaluation summary
| Category | Mutinex |
|---|---|
| 1. Marketing Data Reporting via conversational AI | 4.0 / 4 |
| 2. Historical Performance Insights & Causal Explanation via conversational AI | 4.4 / 5 |
| 3. Channel-Level Optimization with conversational AI | 4.5 / 5 |
| 4. Campaign & Ad Set-Level Optimization for Digital Channels with conversational AI | 1.0 / 6 |
| 5. Incrementality Testing with conversational AI | 0.1 / 5 |
| 6. Agentic Execution & Autonomy | 0.1 / 4 |
| 7. AI's UX & Conversational Interface | 4.0 / 8 |
| 8. Analytical Backbone of the Conversational AI | 2.3 / 4 |
| 9. Enterprise-Grade Platform | 4.0 / 7 |
| Total score out of 48 | 24.4 |
Scoring reflects evidence found by Claude and ChatGPT in publicly available documentation as of June 2026. A score of 0 means the LLMs could not verify a capability from public sources, not that the capability does not exist.
Strengths: Categories with highest scores in this research
-
Channel-level optimization via conversational AI. Mutinex scores 4.5 / 5 in this category.
-
Historical Performance Insights & Causal Explanation via conversational AI. Mutinex scores 4.4 / 5 in this category.
-
Marketing Data Reporting. Mutinex scores 4.0 / 4 in this category.
Limitations: Categories with lowest scores in this research
-
Campaign and ad-set-level optimization for digital channels via conversational AI. Mutinex scores 1.0 / 6 in this category.
-
Incrementality testing capabilities via conversational AI. Mutinex scores 0.1 / 5 in this category.
-
Agentic execution and autonomy. Mutinex scores 0.1 / 4 in this category.
Best for
Mutinex is best for large enterprises who require an AI tool for optimizing media spend across channels. Mutinex is particularly strong in the CPG / FMCG segment.
Frequently Asked Questions (FAQ)
1. What are Conversational AI tools for MMM and Incrementality Testing?
AI tools for MMM and Incrementality Testing help marketers measure media performance, optimize marketing spend allocation and execute optimization actions through a conversational, natural language interface.
2. What are the best-performing Conversational AI tools for MMM and Incrementality Testing?
Sellforte, Lifesight and Triple Whale are currently the leading AI tools for MMM and Incrementality Testing, based on the 48-criteria evaluation in this article.
3. Which Conversational AI tool for MMM and Incrementality Testing is best for enterprise brands?
Based on this evaluation's LLM-based scoring, Sellforte received the highest scores for enterprise brands. Claude and ChatGPT found that Sellforte's conversational AI covers enterprise use-cases from channel-level spend optimization to tactical campaign-level bidding parameter optimization. Sellforte scored 5.5 out of 7 on the Enterprise-Grade Platform category, with Claude and ChatGPT finding public evidence of a large list of reference customers from $1B+ revenue brands, high-grade IT security, US and EU data residency options, multi-cloud deployment across AWS, GCP, and Azure, SSO, and LLM inference isolated inside customer-specific cloud infrastructure.
4. What is the difference between a conversational AI tool for MMM and Incrementality Testing and a generic AI chatbot like ChatGPT or Claude?
Generic AI chatbots like ChatGPT, Claude, and Gemini are not connected to your actual marketing data or measurement models. They can answer general questions about marketing concepts, but they cannot tell you what your incremental ROAS was on Meta last month, recommend an optimal budget allocation for your specific channels, or execute a bidding change on Google Ads. Conversational AI tools for MMM and Incrementality Testing are purpose-built for marketers, grounded in the advertiser's actual data and connected to incrementality-based measurement models such as Bayesian MMM and geo lift experiments.
5. Which conversational AI tool is best for campaign and ad set-level optimization?
Sellforte received the highest scores in this comparison for campaign and ad set-level optimization capabilities. Based on publicly available documentation, Claude and ChatGPT found evidence that Sellforte surfaces incremental ROAS for each campaign and ad set, compares it to last-click and platform-reported ROAS, and recommends optimal spend and bidding parameters at the campaign and ad set level.
6. Which conversational AI tool for MMM and Incrementality Testing is best for ecommerce and DTC brands?
The best choice depends on the size and requirements of the ecommerce brand. Sellforte is a strong option for mid-market and enterprise ecommerce brands (roughly $50M+ in revenue) that need both channel- and campaign-level optimization grounded in enterprise-grade MMM. Triple Whale is a strong option for small and mid-sized DTC brands that prioritize a strong AI and conversational UX but do not yet require enterprise-grade MMM or campaign-level incrementality optimization.
7. What is agentic MMM, and which tools support it?
Agentic MMM refers to AI tools that have a robust Marketing Mix Modeling system under the hood, which is accessed by specialized execution-focused agents. These agents recommend media spend allocation changes, bidding changes, and can autonomously execute those changes on ad platforms. Strongest Agentic MMM platforms in this research were Sellforte and Triple Whale.
8. Sellforte vs. Triple Whale: Which is a better conversational AI tool for MMM and Incrementality Testing?
Sellforte and Triple Whale are the two highest-scoring tools in this comparison, but they serve different needs. Sellforte scored 36.3 out of 48, and Triple Whale scored 32.6 out of 48.
According to this evaluation's LLM-based scoring, Sellforte leads in robustness of analytics, with Claude and ChatGPT finding strong public evidence of full-scale enterprise-grade MMM, incrementality testing and incrementality-corrected attribution. This enables Sellforte provide high-quality spend optimization on campaign & ad set level through its conversational AI interface. Triple Whale leads in agentic execution & autonomy, as well as conversational UX. Triple Whale is the better fit for smaller ecommerce brands that prioritize agentic execution and a strong conversational UX, but who do not require best-in-class incrementality based analytics. Sellforte is the better fit for mid-market and enterprise-grade marketing teams requiring best-in-class analytics and robust spend optimization.
9. What is Bayesian MMM, and why does it matter for AI tools in marketing measurement?
Bayesian Marketing Mix Modeling (MMM) is a statistical methodology for measuring the causal impact of marketing spend on sales. Unlike last-click attribution or platform-reported ROAS, which systematically overstate the contribution of lower-funnel channels, Bayesian MMM estimates true incremental impact across all channels simultaneously. For AI tools, Bayesian MMM is the analytical backbone that enables credible optimization recommendations. Without it, an AI can only report raw data rather than recommend where to allocate budget to maximize incremental revenue.
10. How were the 48 evaluation criteria in this comparison derived?
The 48 criteria were derived from three sources. First, 1,660 real prompts made by marketers and marketing analytics professionals in Sellforte, categorized by topic and use case. Second, AI-related statements and requirements from more than 700 discussions with Sellforte customers and prospects, including marketers, analytics leads, and data scientists from retail, ecommerce, DTC, travel, and restaurants — as well as recent marketing measurement RFP documentation. Third, a review of 78 vendors in the marketing measurement space to identify the range of existing AI capabilities. The combination of these three lenses produced a framework grounded in real usage patterns and real buyer expectations, rather than vendor marketing claims.
11. What is the difference between channel-level optimization and campaign and ad set-level optimization in AI tools?
Channel-level optimization means that the AI recommends how to allocate media budget across channels, for example, shifting spend from Meta to YouTube. This is where most AI tools in this comparison operate. Campaign and ad set-level optimization goes one level deeper: the AI recommends optimal spend and bidding parameters for each individual campaign and ad set within a channel, for example, recommending a specific Target ROAS value for each Google Ads campaign. Campaign and ad set-level optimization is more practically actionable because it is the level at which budget changes are actually executed in advertising platforms. It is also technically harder, requiring reliable incremental ROAS estimation at a much more granular level.
Change log
2026 May 26. Research was launched
2026 June 10. Research methodology was changed from Sellforte-based scoring to LLM-based scoring to minimize author bias. Evaluation for vendors was updated.
Evaluation Dates by Vendor and LLM
The table below shows the exact dates when each vendor was evaluated by each LLM. All evaluations were conducted in June 2026.
| Vendor | LLM conducting the evaluation | Evaluation Date |
|---|---|---|
| Fospha | Claude Opus 4.8 | 9 June 2026 |
| Fospha | ChatGPT 5.5 Pro | 9 June 2026 |
| Mutinex | Claude Opus 4.8 | 10 June 2026 |
| Mutinex | ChatGPT 5.5 Pro | 9 June 2026 |
| Triple Whale | Claude Opus 4.8 | 10 June 2026 |
| Triple Whale | ChatGPT 5.5 Pro | 10 June 2026 |
| Lifesight | Claude Opus 4.8 | 10 June 2026 |
| Lifesight | ChatGPT 5.5 Pro | 9 June 2026 |
| Sellforte | Claude Opus 4.8 | 10 June 2026 |
| Sellforte | ChatGPT 5.5 Pro | 10 June 2026 |
Limitations & Disclosures
Author affiliation. This comparison is published by Sellforte, one of the platforms evaluated. We have made every effort to design the evaluation methodology fairly, applying the same evidence standards and scoring instructions to all vendors including ourselves. The actual scoring was conducted by Claude and ChatGPT, not by Sellforte. We encourage cross-referencing our research with vendor documentation, customer references, and independent analyst coverage.
Scope. This comparison primarily focuses on recognized commercial vendors.
Snapshot in time. Vendor capabilities evolve quickly. This comparison reflects publicly available information as of dates specified in the Evaluation dates -section. Features released after that date are not yet reflected.
Corrections welcome. We will revise this comparison regularly. If a vendor believes a score is inaccurate, we welcome corrections with supporting documentation. Please email research@sellforte.com
Recommendation for buyers. Use this comparison as a structured starting point for your own evaluation, not as a final answer. We strongly recommend conducting evaluation calls or demos with vendors to verify fit against your organization's specific requirements. Pricing, services model, regional support, and integrations with your data infrastructure are factors no rubric can fully capture.
Further Reading & Resources
Methodology
- Calibrating Marketing Mix Models with Experiments and Attribution data
- Advertising response curves: What are they and why do you need them?
- What is Causal Marketing Mix Modeling (MMM)?
- Understanding R2 in Marketing Mix Modeling: A Guide for Marketers
- MMM for Ecommerce: How Marketing Mix Modeling (MMM) Works for Online DTC Brands
- What does "Enterprise-Grade" Mean in Marketing Mix Modeling (MMM)?
- What is Incrementality Testing? Guide for Marketers
- Marginal Incremental ROAS (miROAS): What is it? And why does it matter to marketers?
- How Much Ad Spend Is Needed for Marketing Mix Modeling?
AI and Agents in Marketing Measurement
- The Rise of Agentic MMM (Marketing Mix Modeling): How AI Is Transforming Media Optimization
- State of AI in MMM: Only 13% of MMM Vendors Implementing AI
- Webinar: Agentic MMM in Action: The Future of Autonomous Media Planning and Buying in Real Time
Use-cases on media spend optimization
- 11 Benefits of Marketing Mix Modeling (MMM) Every Marketer Should Know
- 6 Reasons eCommerce & DTC Brands Should Use Marketing Mix Modeling (MMM)
- The Shift in Marketing Mix Modeling: Why Campaign-Level Optimization is Taking Over
- The Five Requirements of Autonomous Media Buying and Optimization: M.A.G.I.C.
- Bid Optimization: How to Calculate the Optimal Bid Values for Your Campaigns Using miROAS
- ROAS, iROAS, miROAS: Choosing the Right KPI for Optimizing Media Spend
Original Marketing Measurement Research by Sellforte Labs
- The 3 Danger Zones of Last-Click (And How to Avoid Them)
- How to measure Meta correctly? GA4 vs. MTA vs. MMM
- How to Measure the True Effectiveness of TikTok Ads?
- From Last-click to Marketing Mix Modeling (MMM): Unlock +6.5% more sales
- The Missing 24%: Why MMM Without Promotions Behaves Like Last-Click
Practical hands-on guides
- How to Integrate Experiments Into an MMM Platform: A Practical Guide
- MMM Pilot Best Practices: 4 Steps to Plan, Run & Scale Your Marketing Mix Modeling Pilot
Marketing Measurement Tools, software and vendors
MMM tools, software and vendors for Ecommerce
- Best MMM Tools for Ecommerce Brands: Top 10 Software
- Best Real-Time MMM Tools for Ecommerce Brands: Software That Delivers Instant Marketing Insights
- Top 5 Enterprise MMM Software for Large Ecommerce Brands ($1B+ in Sales)
- Top 5 Mid-Market MMM Software for Medium-Sized Ecommerce Brands ($50M–$1B Revenue)
- Top 5 SMB MMM Software for Small Ecommerce Brands ($0–$50M Annual Revenue)
MMM tools, software and vendors more broadly
- 30 Marketing Mix Modeling Tools for Accelerating Growth
- Meridian vs. Sellforte MMM SaaS: The Complete Comparison
Incrementality testing tools
Sellforte Product Features
- Visit Sellforte demo (no sign-up required): Sellforte demo
- Sellforte AI product page
Playbooks and Research from the industry
- Google: The modern measurement playbook
- Harvard Business Review: Bridging the Marketing Mix Modeling Actionability Gap
- Meta: Operationalizing incrementality: How marketing leaders are aligning their organizations around true impact
- Meta: Calibrating Marketing Mix Modeling with Incrementality Experiments for Cross-Channel Understanding
- Challenges And Opportunities In Media Mix Modeling (2017, Google - Chan et al.)
- Bayesian Methods for Media Mix Modeling with Carryover and Shape Effects (2017, Google - Jin et al.)
- Geo-level Bayesian Hierarchical Media Mix Modeling (2017, Google - Sun et al.)
- Hierarchical Bayesian Approach to Improve Media Mix Models Using Category Data (2017, Google, Wang et. al)
- Bayesian Time Varying Coefficient Model with Applications to Marketing Mix Modeling (2021, Uber - Ng et al.)
- Hierarchical Marketing Mix Models with Sign Constraints (2020, Cheng et al.)
- Bayesian Hierarchical Media Mix Model Incorporating Reach and Frequency Data (2023, Google - Zhang et al.)
- Media Mix Model Calibration With Bayesian Priors (2024, Zhang et al.)
Authors

Lauri Potka is the Chief Operating Officer at Sellforte, with over 15 years of experience in Marketing Mix Modeling, marketing measurement, and media spend optimization. Before joining Sellforte, he worked as a management consultant at the Boston Consulting Group, advising some of the world’s largest advertisers on data-driven marketing optimization. Follow Lauri in LinkedIn, where he is one of the leading voices in MMM and marketing measurement.

Emil Kauppi-Hoyer is Sellforte's Lead AI Engineer, leading the development of Sellforte AI. With a data science background, Emil belongs to Sellforte's engineering leadership. During his Sellforte career, Emil has implemented Marketing Mix Models and incrementality testing solutions to Sellforte's customers, while at the same time developing Sellforte's AI capabilities. Follow Emil in LinkedIn.
.png?width=701&height=132&name=Juha%20Nuutinen%20(701%20x%20132%20px).png)
Juha Nuutinen is the Chief Executive Officer and co-founder at Sellforte, with over 15 years of experience in optimizing marketing spend and promotional activity for the largest advertisers in the world. Before co-founding Sellforte, he worked as a management consultant at the Boston Consulting Group, specializing in promotion optimization. Follow Juha in LinkedIn, where he is actively sharing his views on marketing measurement.

How to Choose a Conversational AI Tool for MMM and Incrementality Testing: 48 Evaluation Criteria

Best Incrementality Testing Tools in 2026: In-depth Vendor Comparison
